
PaperClip AI:把多个智能体组织成一家公司
PaperClip AI 是一个开源多智能体编排框架,把 Claude Code、Codex、OpenClaw 等 agent 放进公司式组织结构,用目标、预算、任务和审批来管理长期工作流。
PaperClip AI 是一个开源多智能体编排框架,把 Claude Code、Codex、OpenClaw 等 agent 放进公司式组织结构,用目标、预算、任务和审批来管理长期工作流。

这是一篇关于 AI 工作流的中文改写:真正的能力不在一次提示词,而在目标、上下文、执行、反馈与评估组成的循环。

这是一篇 OpenCode 与 Claude Code 的中文对比,梳理模型自由、LSP 集成、agent 能力、成本结构与适用场景。

由 Dobby AI Agent 生成的 Micron Technology (MU) 投资分析报告,保留原始仪表盘图表和交互式排版,供付费会员阅读。

这是一份 AionUI 深度研究,介绍它如何用一个桌面 GUI 统一管理 Claude Code、Codex、Hermes、Gemini CLI 等多个 Agent,并通过 Team Mode 支持多智能体协作。

这是一篇 PicoClaw 入门整理,介绍如何安装这个 Go 写成的轻量级 AI 助手,并配置模型、多 agent、工具、Telegram、定时任务与持久记忆。
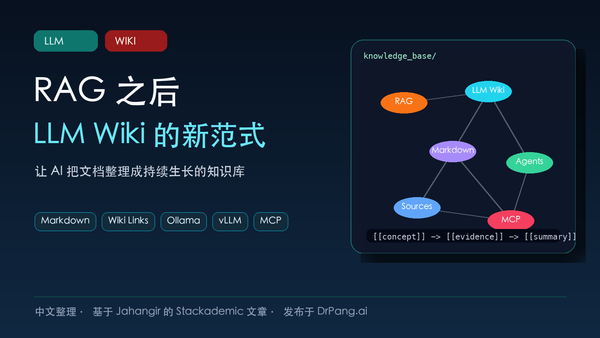
这是一篇关于 LLM Wiki 的中文整理,介绍为什么传统 RAG 不够沉淀长期知识,以及如何用 Markdown、MCP、Ollama 和 vLLM 构建持续生长的 AI 知识库。
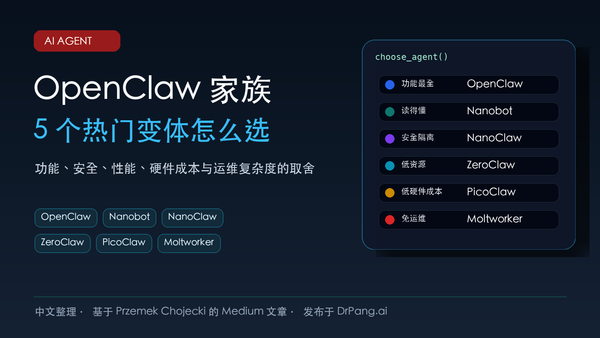
这是一篇 OpenClaw 家族变体选型指南,比较 OpenClaw、Nanobot、NanoClaw、ZeroClaw、PicoClaw 与 Moltworker 在功能、安全、性能、硬件成本和运维复杂度上的取舍。

本文为中文翻译转载,原文作者为 August G. Osei / August_GO,原文发布于 Medium,并同步收录在 August Wheel。原文链接:I Ran OpenClaw and Hermes on the Same Server. Today I Deleted One of Them.。本文保留原文主要结构、图片与观点,并做中文表达整理。 今天,我做了一件几个月前完全没想到自己会做的事:我删掉了自己的 OpenClaw AI 助手 August。可以放点悲伤音乐了。 我是在一月份安装 OpenClaw 的。那时候它的 GitHub star 还没有疯狂起飞,也还没有出现一群人排在中国深圳科技办公室门口,只为了把它装到自己笔记本上的场景。我给自己的 OpenClaw

这是一篇关于 OpenClaw 与 Hermes Agent 路线差异的中文整理,比较二者在平台连接、持续学习、记忆系统、安全风险与组合使用场景上的取舍。
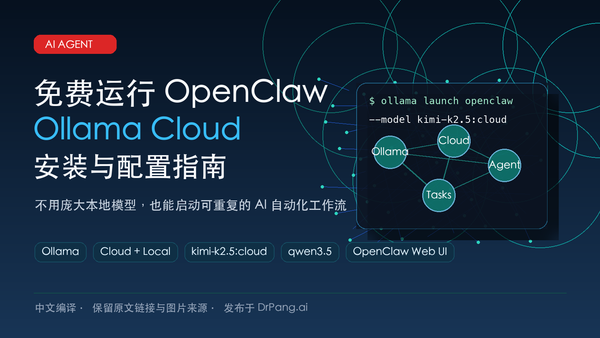
这是一篇面向初学者的 OpenClaw 与 Ollama Cloud 配置指南,介绍如何安装 Ollama、安装 OpenClaw、登录 Ollama 并用云端模型启动 AI 自动化工作流。

这是一篇 Paperclip AI Agent 深度研究报告,介绍其多代理组织架构、预算控制、治理能力、应用场景以及与 AutoGen、CrewAI、LangGraph 的差异。

AI agent
这是一篇 OpenClaw 架构深度解析,介绍三层能力模型、25 个工具、53 个官方 Skills、集成模式与个人及企业自动化应用场景。

AI agent
这是一篇 OpenClaw 工作区文件指南,解释 SOUL.md、AGENTS.md、USER.md、TOOLS.md、HEARTBEAT.md 和 MEMORY.md 如何共同定义 agent 的身份、流程、工具、记忆与定时任务。

AI agent
这是一篇面向初学者的 OpenClaw 免费运行指南,介绍如何用 OpenRouter 免费模型、Dobby API 和 NVIDIA Kimi-k2.5 配置零成本 LLM 工作流。

AI agent
OpenClaw、Paperclip 与 Hermes 都是 2026 年快速走红的开源 AI agent 平台。本文翻译并比较三者在架构、工具生态、记忆、自托管部署、成本和适用场景上的差异,帮助判断哪一个更适合你的工作流。

Hermes Agent
Hermes Agent 在短时间内获得大量 GitHub stars,引发 AI agent 社区关注。本文翻译并介绍作者同时运行 OpenClaw 与 Hermes 的真实经验:agent 框架、记忆、集成和底层模型,都会决定个人 AI 助手是否真正有用。

clawdbot
运行 Clawdbot 意味着你将拥有对隐私、个性化设置和系统稳定性的完整掌控。但与此同时,你也需要自己承担计算、网络传输、存储以及调用大语言模型(LLM)所带来的相关费用。 本指南从实用角度出发,帮助你了解这些成本从何而来、如何随使用量变化,并附带精确示例以便你制定预算。

AI agent
Clawdbot AI 是一款革命性的开源个人助理,它通过完全自托管的部署方式,提供了前所未有的控制力、隐私保障与真实世界自动化能力,正在彻底改变人们管理任务、工作流程和数字生活的方式——而这一切,只需通过你日常使用的聊天工具即可完成。

clawdbot
AI 助手的未来已经来了。但没人愿意谈它的黑暗面。 你还记得《钢铁侠》里托尼·斯塔克和贾维斯对话、动动嘴就搞定一切的场景吗?灯光调暗,系统启动,问题迎刃而解。 现实世界的版本,就是最近火爆全网的Clawdbot (后改名为Moltbot, OpenClaw)。 在深入研究它到底能干什么之后,我必须跟你坦诚聊聊。

人工智能技能
每隔几年,科技界就会发生一次转变。但现在人工智能领域发生的一切比我们过去十年中看到的任何事情都要大。 事实是:到2025年,理解人工智能和不理解人工智能的人之间的差距将以前所未有的速度扩大。 这不是危言耸听,而是现实。 我们正在从“与AI聊天”的时代转向“用AI构建”的时代。如果你想保持竞争力——甚至取得领先——这里有你今年必须学习的9项AI技能。

AI trends 2026
随着人工智能这几年的极速发展,2025年已经清晰地为我们揭示了2026年的技术图谱。从能够自主决策的智能体,到围绕伦理、监管和数据隐私的深入讨论,我们正步入一个**AI从“新奇”转向“实用”**的时代。 企业正在大力投资AI基础设施,政府和社会组织也在积极建立相关的规范和标准,可以预见:2026年将成为AI发展的关键转折点。

prompt engineering
你是不是也遇到过 ChatGPT 老是给你同一个无聊的回答? 这个全新的技巧可以让任何 AI 模型释放 2 倍以上的创造力,不需要任何训练。 让我们看看是怎么做到的

AI job
我们正处于个体创业的黄金时代。科技正在迅速让一人创业变得:更简单,更轻松,更低风险。这对普通人来说,是一个千载难逢的机会。但前提是你要用对方式。