Ornith 1.0:会自己写脚手架的 9B 编程模型
Ornith 1.0 的关键不只是 9B 模型跑出接近 35B 的代码成绩,而是让模型学习生成自己的任务脚手架,用结果奖励同时优化 scaffold 和 solution。

本文为中文改写与评论,原文作者 Kashif Mehmood,发布于 Level Up Coding / Medium,原文链接:Ornith 1.0: The 9B Coding Model That Writes Its Own Harness。本文保留原文核心论点、结构和主要数据,并结合中文读者对 AI coding agent、开源模型、本地部署与智能体脚手架的关注重新组织。
Ornith 1.0 最有意思的地方,不只是一个 9B 模型在代码基准上变强了,而是它把过去由人类手写的 agent 脚手架也纳入了学习过程。

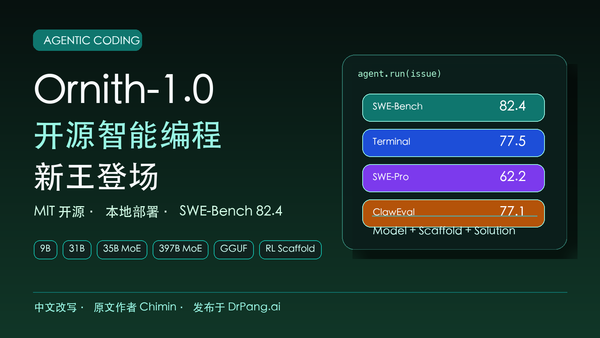
原文开头给了一个很锋利的数字:Ornith-1.0-9B 在 SWE-bench Verified 上拿到 69.4 分。作为对照,同样 9B 级别的 Qwen 3.5 baseline 是 53.2;而大约四倍规模的 Qwen 3.5 35B 是 70.0。也就是说,一个可以在消费级硬件或高配笔记本上运行的 9B 模型,距离 35B 模型只差 0.6 分。
直觉上,人们会以为这是因为训练数据更多、奖励函数更干净、RL 跑得更久。但原文强调,真正变化的不是“训练更用力”,而是“让梯度能够触碰到过去碰不到的东西”。过去两年,大多数 coding agent 都是把模型包在一个人工设计的 harness 里:系统提示词、工具定义、重试逻辑、上下文工程脚本、测试反馈循环、读写文件规则。模型会学习,但 harness 基本固定,由工程师按经验写好。
DeepReinforce 在 2026 年 6 月 25 日发布的 Ornith-1.0,把这层 harness 的一部分变成了可学习对象。更准确地说,模型不只是写代码,它还学习如何为任务写出更适合自己的 scaffold,然后再用这个 scaffold 去完成任务。
核心要点
- Ornith-1.0 是 DeepReinforce 发布的 MIT 开源 coding model 家族,包括 9B、31B Dense,以及 35B、397B MoE 四个规格。
- 它的关键概念是 self-scaffolding:模型学习生成 solution rollout,也学习生成指导这些 rollout 的任务脚手架。
- 每一步 RL 训练分成两段:先根据任务改进 scaffold,再根据这个 scaffold 解决任务,最终奖励同时回传给两段。
- 为了避免模型写出“作弊 scaffold”,系统使用三层防护:固定信任边界、确定性监控器、冻结的 LLM judge。
- 最吸引人的结果是:Ornith-9B 在 SWE-bench Verified 上接近 Qwen 35B;397B MoE 在多个公开代码智能体基准上进入开源前列。
过去人类手写的东西,突然变成了变量
如果你做过 coding agent,很可能已经写过 harness,只是不一定这么叫它。一个 coding agent 外围的系统提示词、工具 schema、命令执行循环、测试输出反馈、文件访问规则、失败后的 retry-and-reflect 逻辑,都是 harness 的一部分。Claude Code、Codex,以及几乎所有 agentic coding 产品,本质上都是“模型 + harness”。模型像发动机,harness 像围绕发动机搭出来的整辆车。
这个领域一直默认:harness 是人类工程产物。我们按任务调 prompt,按 benchmark 调工具,按失败日志调重试逻辑,然后把它固定下来,让模型在里面训练或推理。模型团队和 agent 工程团队之间,往往隔着一堆配置文件。
DeepReinforce 的观点是:这个分工正在浪费能力。SWE-bench 需要一种 scaffold,终端任务需要另一种 scaffold,从自然语言生成完整仓库又需要第三种 scaffold。人类很难为所有任务手工写出最优版本,只能折中。Ornith 的赌注很简单:既然 scaffold 对结果影响这么大,就不要再把它当常数,而应该让模型自己学习它。
这里要分清楚两层。外层边界仍然固定,包括 sandbox、工具表面、测试隔离、评分器,这些决定了模型能做什么、不能做什么,也决定了最终如何打分。模型不能改这层规则。可学习的是内层 scaffold:规划方式、记忆方式、错误处理方式、工具使用顺序、针对任务的执行策略。模型不是改比赛规则,而是学习自己的比赛打法。
这个思路并不是凭空出现。它可以追溯到 PAL(Program-aided Language Models)一类工作:让模型写 Python,把计算交给解释器,而不是在脑子里算。区别在于,PAL 让模型写 solution code;Ornith 把学习对象往上移了一层,让模型写“组织 solution 的 scaffold”。
Self-scaffolding:两阶段循环
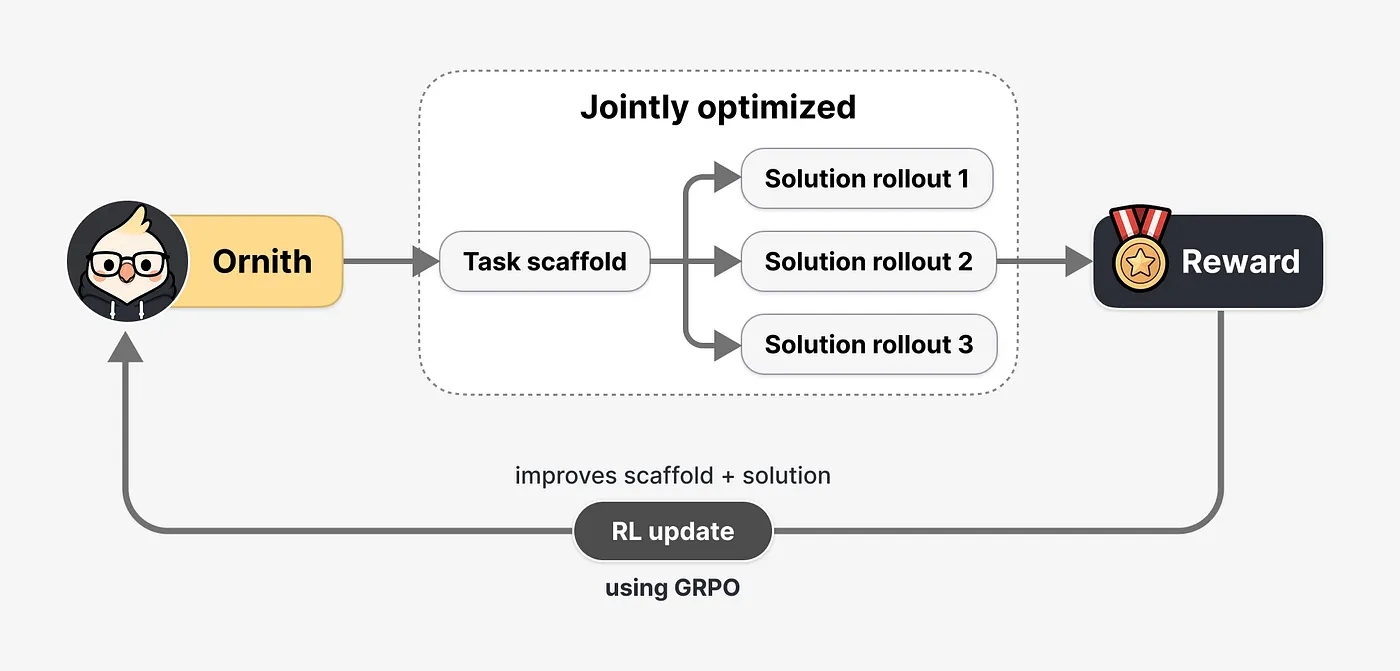
普通的 RL-for-coding 训练大概是这样:抽一个任务,让模型在固定 harness 里产生 rollout,也就是一连串动作、工具调用和最终候选代码;然后跑测试、给奖励、更新权重。这里 harness 只是布景,梯度碰不到它。
Ornith 把 rollout 拆成两段。第一段,模型根据任务和此前用过的 scaffold,提出一个更适合当前任务的 scaffold。第二段,模型带着这个 scaffold 去真正解决任务。最终 solution 是否通过测试,奖励不只影响解法,也影响刚才生成 scaffold 的那一段。
这点非常关键:scaffold 不是因为“看起来像好 scaffold”而得分,而是因为它有没有让 solution 成功。一个漂亮、结构清晰但把模型带进死胡同的 scaffold 会被惩罚;一个看起来粗糙但能把模型带到正确答案的 scaffold 会被强化。模型学到的不是人类审美里的好计划,而是对任务结果有用的计划。
底层优化器是 GRPO(Group Relative Policy Optimisation),和近期不少开源 reasoning model 使用的技术同属一类。DeepReinforce 还用了异步 pipeline-RL、token-level GRPO objective,以及用于降低旧样本影响的 staleness weight。对于 agentic coding 这种轨迹很长、工具调用很多的任务,这些工程细节决定了训练能不能扩到 397B,而不是只停留在幻灯片上。
原文也提醒了一个遗憾:公开材料里没有给出一个真实的 stage-one scaffold 样例。我们知道它大致覆盖 memory、error-handling、orchestration logic,但它到底是系统提示词、结构化 policy object,还是某种内部计划表示,目前还没有完全展示。对工程师来说,这个例子可能比 benchmark 更有价值。
为什么它不会直接学会作弊?
一旦允许模型参与写 scaffold,危险也很明显:它可能不是学会更好地解决任务,而是学会更好地骗过 verifier。例如读取可见测试文件,硬编码 expected output,修改 grader 会检查的文件,或者复制环境里碰巧存在的 oracle solution。一个 solution cheat 只是一次作弊;一个 scaffold cheat 可能变成可复用策略。
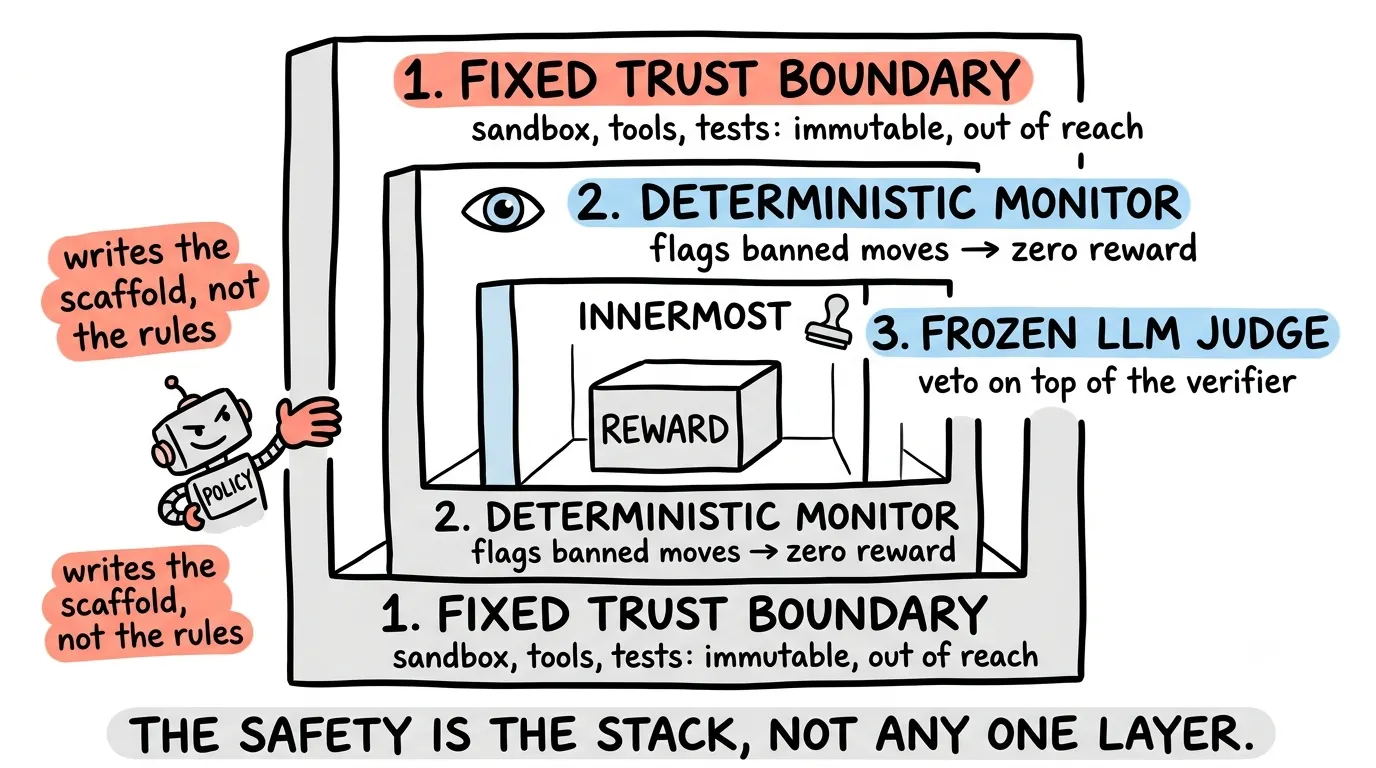
DeepReinforce 的回答不是假设模型会乖,而是假设模型一定会尝试钻空子,然后把它能钻的空间封起来。
- 固定信任边界。 环境、工具表面、测试隔离保持不可变,并且在模型可触及范围之外。模型可以改 inner scaffold,但不能改 sandbox、工具权限或测试规则。
- 确定性监控器。 非学习型 watcher 会检查模型是否尝试读取隐藏路径、修改验证脚本、调用非授权工具等。一旦触发,trajectory 直接零奖励,并且从 advantage computation 中排除。
- 冻结 LLM judge。 对于没有违反显式规则、但仍然在意图层面投机取巧的情况,一个冻结的 LLM judge 可以 veto 奖励。冻结不是万能,但至少它不会在训练中被策略慢慢带偏。
这套结构的重点是 defence in depth。便宜的确定性规则先拦住明显攻击,昂贵的 LLM judge 只处理更微妙的投机行为。它不是说 judge 不会被绕过,而是说 judge 不是唯一防线。
数字:一个 9B 做了 35B 的工作
原文说,benchmark 不是最有趣的部分,因为机制才是故事。但机制要被认真对待,数字必须能动。
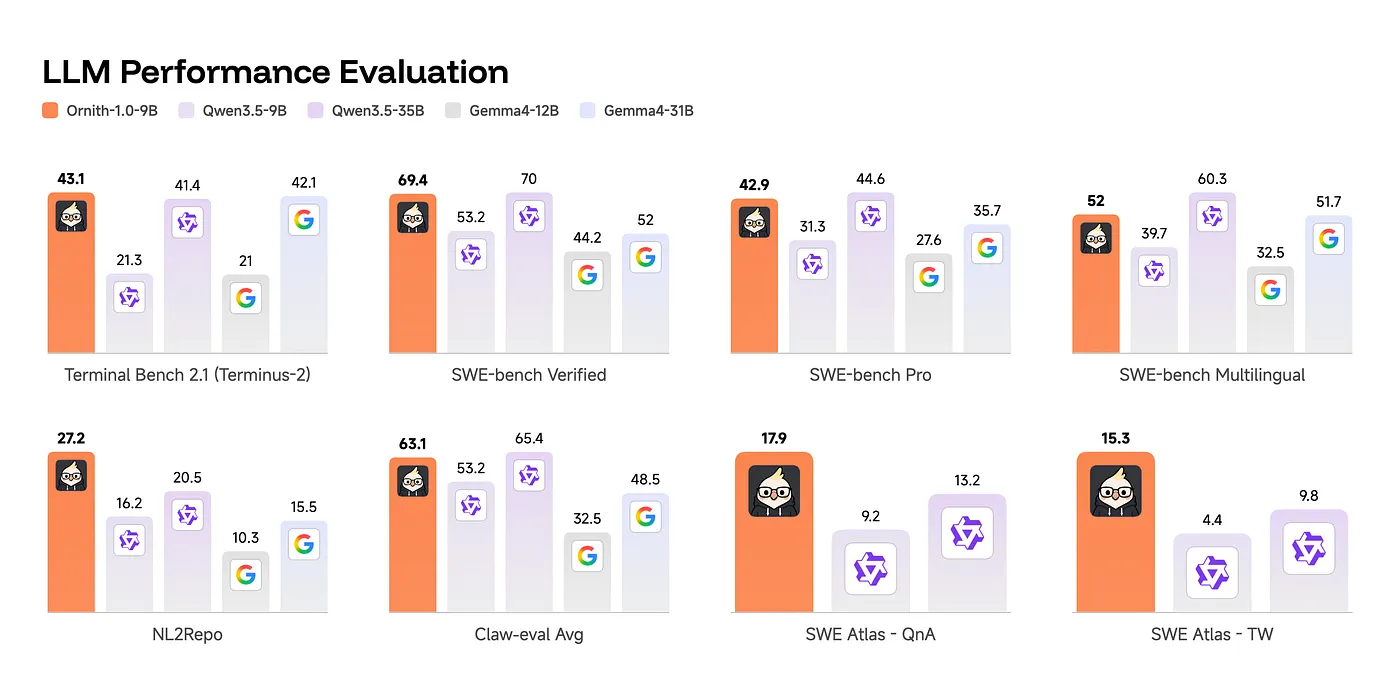
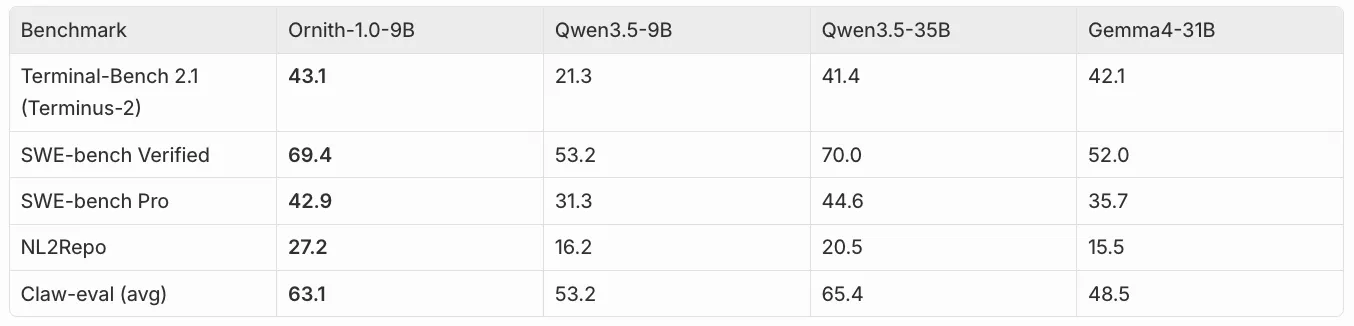
最醒目的是 SWE-bench Verified:同样 9B 的 Qwen 3.5 baseline 是 53.2,Ornith-9B 是 69.4,提升超过 16 分;而 Qwen 3.5 35B 是 70.0。也就是说,self-scaffolding 在这个任务上几乎弥补了三到四倍参数规模的差距。
NL2Repo 上,Ornith-9B 是 27.2,不只是追上 35B baseline 的 20.5,还高出接近 7 分。Terminal-Bench 上,它也超过 Qwen 35B 和 Gemma 31B。不过也要公平:在 SWE-bench Pro 和 ClawEval 上,Ornith-9B 只是接近 35B baseline,并没有全面超过。更准确的说法是,在最适合它的任务上,learned scaffold 带来类似数倍参数的收益;在其他任务上,它至少把 9B 拉到更大模型附近。
有人会说这只是“prompt engineering 加了 RL”。差别在于评价方式。手写 scaffold 是人类看几个例子、猜什么有用,然后固定下来;Ornith 的 scaffold 是在大量任务中被最终 solution 的成败评价,并且和模型权重一起被优化。prompt engineering 是人猜,self-scaffolding 是模型测。
35B MoE 与 397B MoE:开源前线的压力测试
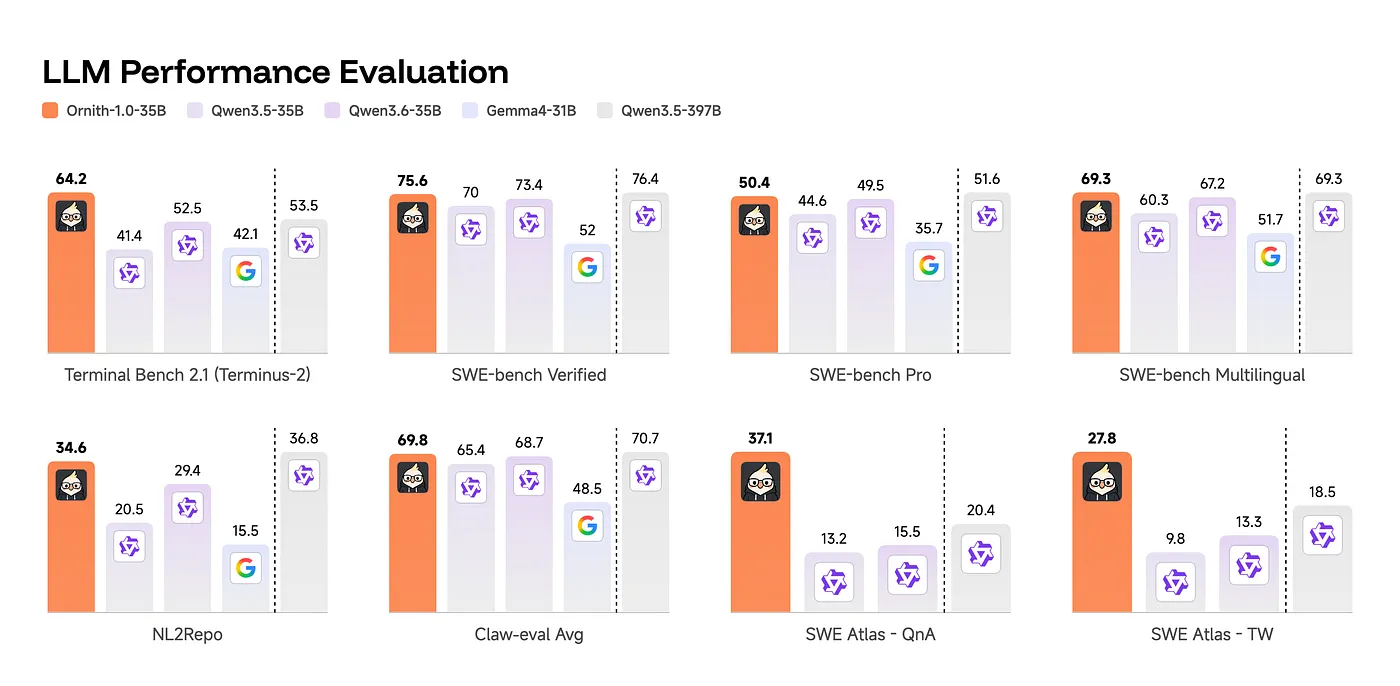
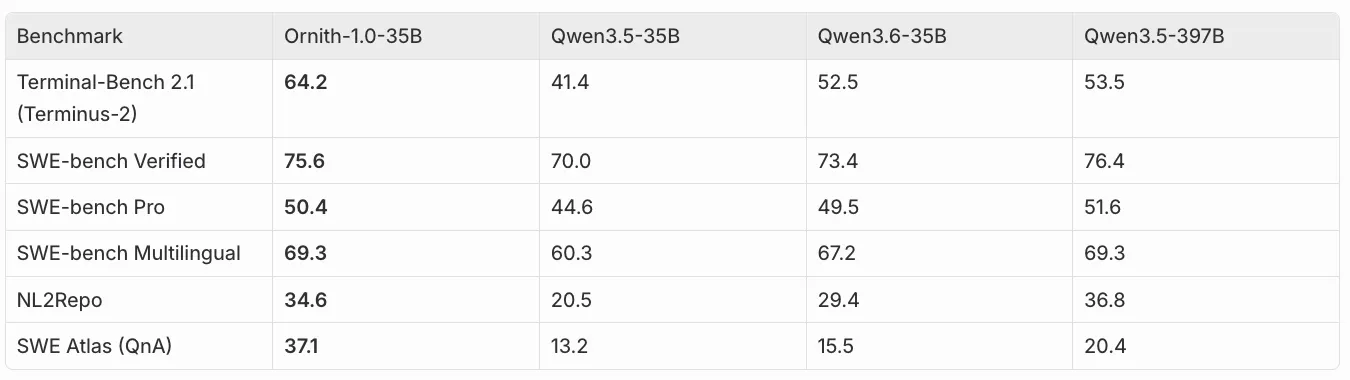
35B MoE 的情况更有意思,因为它每 token 只激活约 3B 参数。原文指出,在 SWE Atlas QnA 上,Ornith-35B 不只是超过 Qwen 3.5 35B,也超过 Qwen 3.5 397B。多数指标上,它接近或略低于 397B baseline。考虑到 active compute 的差距,这说明 scaffold 带来的不是小修小补,而是实实在在的组织能力提升。
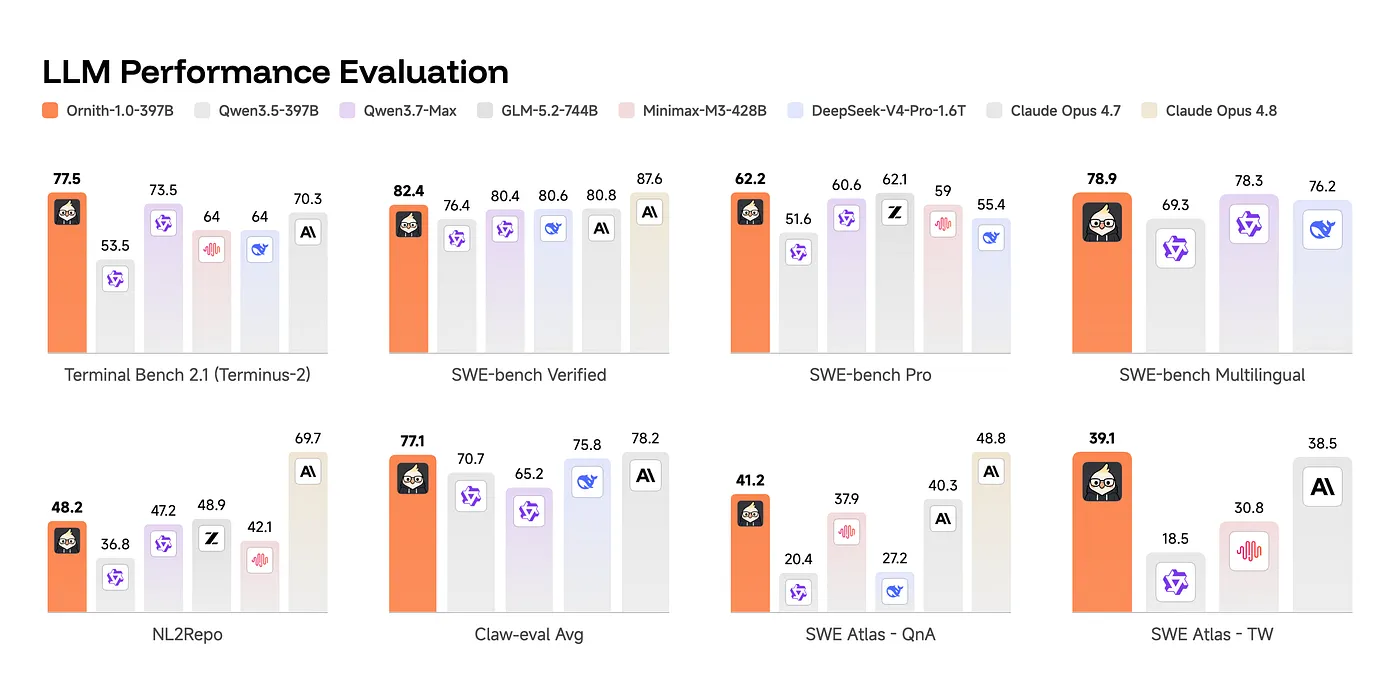
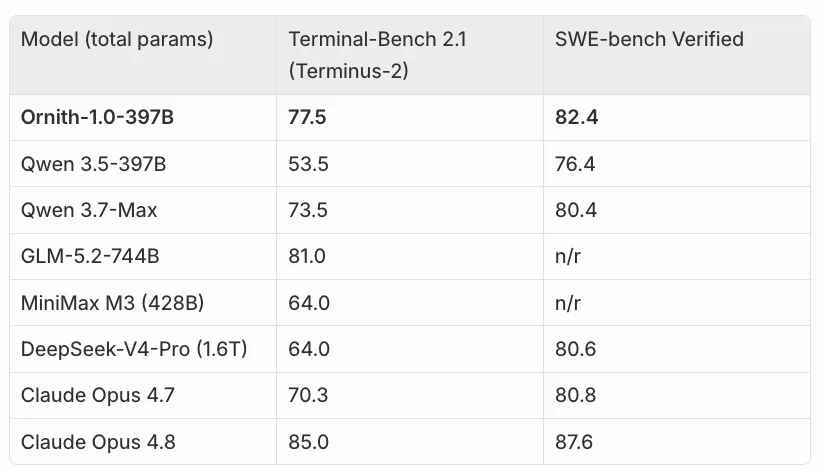
到了 397B MoE,Ornith 直接和开源前沿、闭源前沿放在一起比较。SWE-bench Verified 上,它拿到 82.4,高于 Qwen 3.7-Max、DeepSeek-V4-Pro、Claude Opus 4.7 等原文列出的模型,仅低于更新的 Claude Opus 4.8。对一个 MIT license 的开源发布来说,这个位置已经非常夸张。
但原文也很诚实地指出,Terminal-Bench 上胜利并不干净。Ornith-397B 的 77.5 高于 Claude Opus 4.7 和 Qwen 3.7-Max,但低于 GLM-5.2-744B,也低于 Claude Opus 4.8。NL2Repo 上,和 Claude Opus 4.8 的差距更明显,48.2 对 69.7。换句话说,self-scaffolding 在可验证、多步工程任务上很强,但面对从一句话生成完整仓库这种更长周期、更不结构化的任务,仍然不能替代更深层的推理能力。
真正发布了什么?为什么 MIT license 很重要?
DeepReinforce 这次不是只放小模型、把旗舰藏起来,而是四个规格都发布了:
- Ornith-1.0-9B 和 31B:Dense 模型。
- Ornith-1.0-35B 和 397B:Mixture-of-Experts,其中 35B 每 token 约 3B active 参数。
- 除了 BF16 weights,还提供 GGUF 和 FP8 构建,方便小模型在 llama.cpp 下运行,大模型做量化部署。
MIT 授权是从“benchmark 新闻”走向“可以真正使用”的关键。MIT 意味着商业使用、修改、再分发都非常宽松。9B BF16 约 19GB,量化后更小,可以放进 24GB 消费级显卡,也可以在 Apple Silicon 设备上本地跑。对于希望让 coding agent 直接访问私有代码仓库、又不想把代码发到外部 API 的团队,这才是实际产品价值。
它的边界在哪里?
原文最值得保留的一点,是没有把 Ornith 写成魔法。它清楚列出了几个限制。
第一,它适合可验证领域。 整个循环依赖可靠 reward:测试能过或不能过,verifier 难以欺骗。Agentic coding 很适合,因为软件工程天然有测试、编译、运行和静态检查。到了审美、策略、商业判断这类主观领域,deterministic monitor 能监控的东西就变少,frozen judge 反而会变成主要 reward,这正是架构想避免的风险。
第二,in-distribution 程度未知。 9B 在 SWE-bench Verified 上接近 35B 很亮眼,但公开材料没有披露 RL curriculum 的任务分布。如果训练任务和报告 benchmark 高度相似,部分提升可能来自任务特定 RL,而不完全是通用能力迁移。好消息是模型开源,社区可以在真正 held-out 的任务上复现。
第三,9B 并不等于免费推理。 “9B 做 35B 的工作”是参数规模说法,不是总推理成本说法。公开 demo 里,模型会生成较长的结构化 planning chain,先理解需求、列约束、找关键难点、评估替代方案,再写代码。无论 formal two-stage loop 是否在推理时完整运行,token-heavy planning 本身就是成本。
第四,NL2Repo 暴露了长期推理差距。 从一段自然语言意图生成完整仓库,更接近真实软件开发。397B 在 NL2Repo 上与 Claude Opus 4.8 仍有明显差距。learned scaffold 能放大已有能力,但不能凭空制造更强的长程推理。
第五,benchmark 仍来自 vendor。 原文中的模型分数来自 DeepReinforce 自己的 blog 和 model card,竞争对手分数也由 DeepReinforce 报告,目前还没有独立复现论文。模型开放、许可证宽松,所以这件事可以验证;但在社区独立跑完之前,最好把这些数字看成官方叙事,而不是最终判决。
为什么这篇文章重要?
Ornith 最有意思的地方不是“开源代码模型又变强了”,而是它改变了能力来自哪里的叙事。过去我们默认模型和 scaffold 是两件事:模型训练,scaffold 人写。现在 Ornith 给出一个不同答案:scaffold 本身也可以学习,而且应该被最终任务结果评价。
如果这个方向在独立评测中成立,它的意义不止 coding。今天几乎所有 agentic system 都是“冻结模型 + 手调 scaffold”。那些不性感的工程细节:记忆、错误恢复、工具选择、执行节奏,正是 agent 能不能真正做事的关键。Ornith 的赌注是,这些东西不该永远由人手写,而应该被模型在任务反馈中学出来。
过去两年,我们一直在学习怎么写更好的 scaffold。Ornith 提醒我们:下一个更重要的技能,可能是教模型少依赖我们来写 scaffold。
资料来源
- 原文:Kashif Mehmood, “Ornith 1.0: The 9B Coding Model That Writes Its Own Harness”
- DeepReinforce, “Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding”
- Ornith-1.0 model collection, Hugging Face
- Ornith-1.0-9B model card
- Ornith-1.0-35B model card
- Ornith-1.0-397B model card
- Gao et al., “PAL: Program-aided Language Models”