成为 Top 1% Claude Code 用户:从提示词到工程系统
这是一篇 Claude Code 高级工作流的中文改写:把 CLAUDE.md、hooks、subagents、MCP 和 review 流程组合起来,把 Claude Code 从提示词工具升级为工程系统。
本文为中文改写与评论,原文作者 allglenn,原文发布于 Towards AI,时间为 2026 年 4 月 11 日,原文链接:Becoming a top 1% Claude Code user: the complete playbook no one else is sharing。本文保留原文核心结构与观点,并结合中文开发者使用 Claude Code、Codex、OpenClaw、MCP 和多智能体工作流的实际场景做了重新组织。
多数人把 Claude Code 当成更聪明的自动补全。真正的高手把它当成一套可编程的软件工程基础设施。

你可能只用到了 Claude Code 的 20%
很多开发者第一次用 Claude Code 的方式都很像:打开终端,输入 claude,描述一个功能,然后等 Claude 写文件、改代码、跑测试。它确实比传统搜索和复制粘贴快很多,所以很容易让人产生一种“我已经很会用了”的错觉。
但真正的问题是:你仍然在手动管理所有上下文、决策、质量检查和后续动作。Claude Code 只是帮你更快地完成步骤,而不是改变整个开发系统。
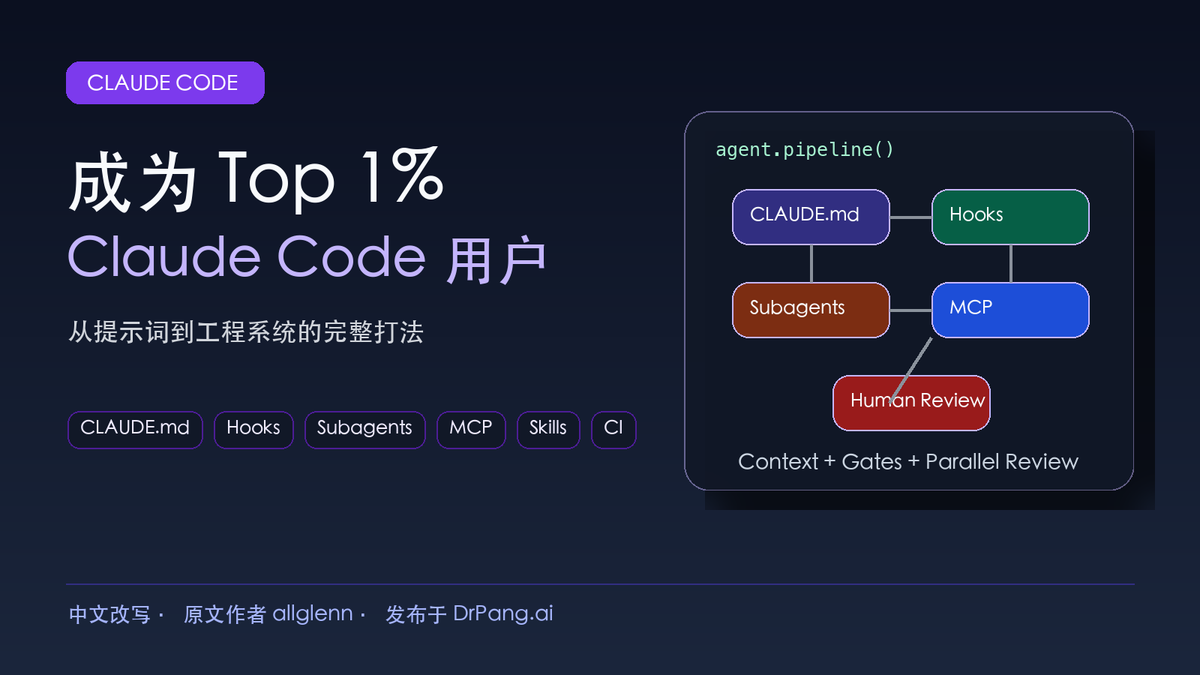
顶级用户的区别不在于他们会写更花哨的提示词,而在于他们设计了系统:每个项目都有精简的 CLAUDE.md,每次会话自动加载正确背景;每次写文件后有 hooks 自动跑 lint;复杂任务交给多个 subagent 并行处理;MCP 服务器让 Claude 能读取 GitHub、数据库、Jira 或内部工具,而不是靠人类复制粘贴。
换句话说,Claude Code 的上限不只是“帮你写代码”,而是成为一个可以被配置、被约束、被审计、被编排的工程团队。
Claude Code 不是编码助手,而是 agent 编排框架
如果只把 Claude Code 理解成“能在终端里写代码的聊天机器人”,你会低估它。更准确的说法是:Claude Code 是一个面向软件工程的 agent orchestration framework,只是它最擅长的场景刚好是写代码。

原文把 Claude Code 的能力分成几个层次:CLI/IDE 入口、项目上下文、文件读写与命令执行、hooks、subagents、MCP、skills、slash commands 等。普通用户只用最表层:让 Claude 改几个文件。高级用户则把这些层叠起来使用,于是产生复利。
这一点和我们在 OpenClaw、Codex、Dobby 这类 agent 平台里看到的趋势类似:模型本身当然重要,但真正决定产出的,是你是否有一套稳定的工作流和边界。
Claude Code 与 Copilot、Cursor 的本质区别
AI 编程工具已经非常拥挤:GitHub Copilot、Cursor、Windsurf、Codeium、Amazon Q,各有强项。Claude Code 的定位不是“又一个编辑器插件”,而是项目级工作系统。
GitHub Copilot 很适合行级补全。它快、自然、嵌在 VS Code 里,尤其适合小改动。但它缺少长期项目记忆,也没有完整的命令执行、测试循环和架构级决策能力。你仍然是所有步骤之间的胶水。
Cursor 把 Copilot 的能力扩展到了多文件修改和更好的 GUI 体验。它对中等复杂度任务很顺手,但仍然更像一个编辑器环境,而不是一套可以被 hooks、subagents 和外部工具编排的系统。
Claude Code 的强项在项目级别。它可以读代码库、计划多文件修改、执行命令、跑测试、读错误、修复、再跑。更关键的是,它有 CLAUDE.md 记忆、hooks 自动化、subagents 并行、MCP 外部连接,运行入口也不限于一个编辑器。
一句话概括:Copilot 和 Cursor 是你使用的工具;Claude Code 更像你配置和调度的系统。
CLAUDE.md:不要写百科全书,要写作战简报
每个 Claude Code 会话开始时都接近“从零开始”。CLAUDE.md 是少数会被自动加载的项目记忆,因此它非常关键。但很多人犯的第一个错误,就是把它写成项目百科全书。
原文给了一个很重要的提醒:CLAUDE.md 的有效指令预算有限。系统提示词本身已经占用一部分,剩下的每一行都应该服务于“如果没有这行,Claude 会不会在我的项目里犯错”。如果答案是否定的,这行就该删。

好的 CLAUDE.md 通常包含三类信息:
- What:项目技术栈、依赖、入口文件、测试命令。不要复制整个
package.json,只要引用它。 - Why:关键架构选择背后的原因。比如“我们使用 SSR,因为目标用户网络很慢”,比“使用 SSR”有用得多。
- How:Claude 在这个项目里最容易犯的错,以及应该采用的正确做法。
一个被低估的技巧是目录级 CLAUDE.md:
~/.claude/CLAUDE.md # 全局规则,适用于所有会话
./CLAUDE.md # 项目根目录,建议提交到 git
./CLAUDE.local.md # 个人规则,加入 .gitignore
./src/api/CLAUDE.md # API 目录规则,按需加载
./src/db/CLAUDE.md # 数据库目录规则,按需加载不要把所有模块约定都塞到根目录文件。把 API、数据库、前端、部署等模块规则放在对应目录,Claude 进入相关区域时再加载。这样既省上下文,也减少指令冲突。
CLAUDE.md 的反模式
第一,写得太长。 超过两百行后,Claude 很可能开始丢指令。不是模型“不听话”,而是你给了太多同等重要的信息。
第二,记录 Claude 本来就会做对的事。 如果它从来不会把 TypeScript 项目写成 CommonJS,就不要浪费一行写“使用 TypeScript”。把预算留给真实错误。
第三,只写禁止,不写替代。 “不要使用某个参数”不够好,最好写成“不要使用 A,遇到这种情况用 B”。禁止本身不会形成可执行路径。
第四,把强制行为放进 CLAUDE.md。 如果某件事必须发生,比如权限、模型选择、强制审批、命令限制,应该放进 settings.json 或 hooks。CLAUDE.md 是建议,settings 和 hooks 才是制度。
Hooks:把质量门禁从“提醒”变成“机制”
Hooks 是 Claude Code 从工具变成基础设施的关键。它们是在特定生命周期节点自动运行的 shell 命令:写文件前、写文件后、执行命令前、会话结束时、subagent 结束时等。
最重要的一点是:hooks 不依赖 Claude 的判断。它们会自动执行。这意味着你可以把 lint、format、安全命令拦截、会话总结、CI 队列推进等流程制度化。
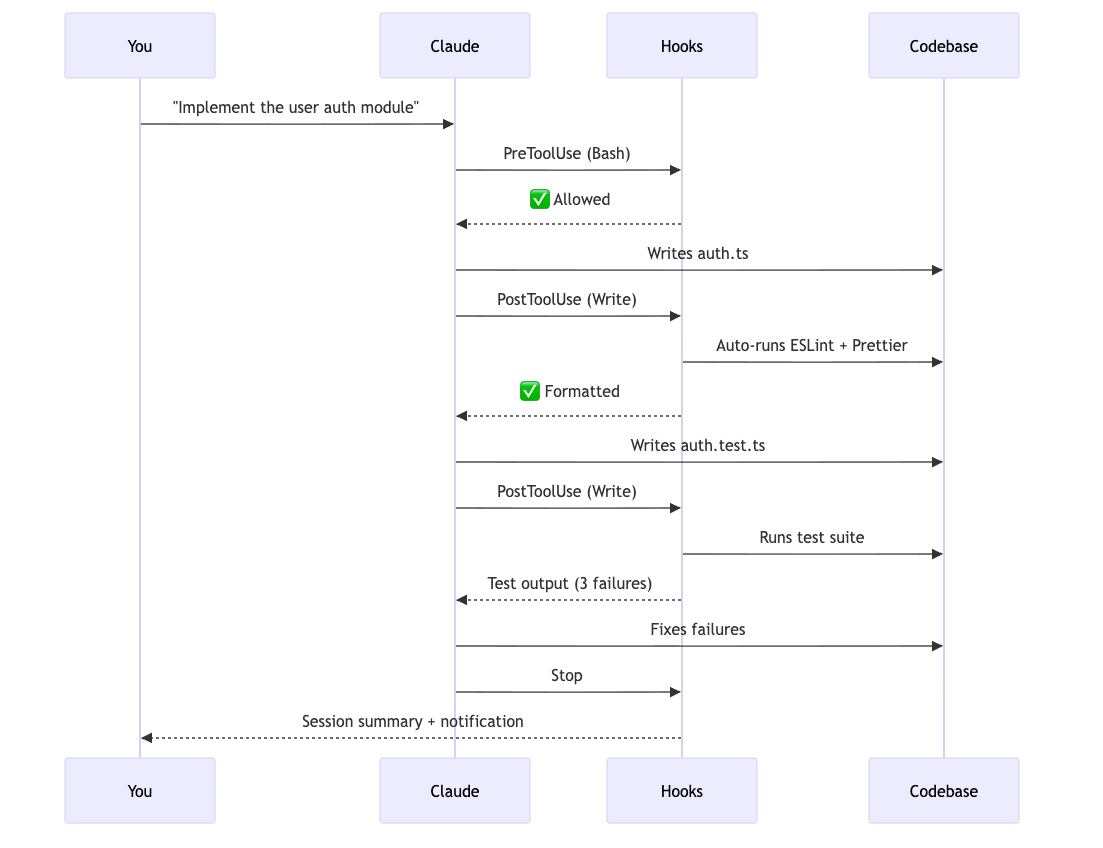
一个典型的起步配置是:Claude 写完文件后自动跑 lint;Claude 执行 Bash 前先检查危险命令;会话结束时生成摘要。
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write",
"hooks": [
{
"type": "command",
"command": "cd $PROJECT_ROOT && npm run lint --fix"
}
]
}
],
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "python .claude/hooks/block_dangerous.py"
}
]
}
]
}
}block_dangerous.py 可以从 stdin 读取将要执行的命令,拦截 rm -rf、git push --force、DROP TABLE 等操作。退出码为 2 时,错误信息会回到 Claude 的上下文里,形成可见反馈。
这类机制的价值很大:你不再需要每次提醒 Claude“别忘了跑 lint”“别执行危险命令”。系统会做。
Subagents:让主会话保持清醒
Subagents 是 Claude Code 最有杠杆的能力之一。它允许你运行多个专门的 Claude 实例,每个实例有自己的上下文窗口、系统提示词、工具权限,甚至可以指定不同模型。
主会话负责架构判断和方向控制,复杂的搜索、代码审查、安全审计、测试生成交给独立 subagent。这样主会话不会被大量细节污染,subagent 也能用更聚焦的标准完成任务。
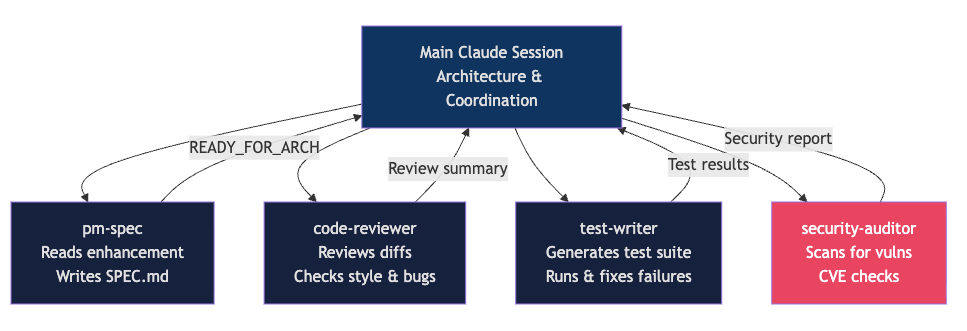
一个代码审查 subagent 可以这样设计:
---
name: code-reviewer
description: Reviews code for correctness, security, performance, and maintainability.
tools: Read, Grep, Glob, Bash
model: claude-opus-4-6
---
You are a staff engineer doing a thorough code review.
For each changed file, check:
1. Correctness
2. Edge cases
3. Security
4. Performance
5. Readability
Output a structured report with MUST FIX, SHOULD FIX, and CONSIDER sections.这里的关键不是“多开几个 Claude”,而是角色隔离和权限隔离。研究员可以只读;代码审查员可以读和跑测试;实现者可以写文件;发布 agent 才能碰部署脚本。
两个 Claude 做 code review
原文里最实用的技巧之一,是“两会话审查模式”。Session A 负责实现功能,它知道上下文,也知道自己为什么做了某些权衡。正因为如此,它容易为自己的捷径辩护。
Session B 从零开始,只读 diff,像一个冷启动的资深工程师一样审查。它没有 Session A 的心理负担,所以更容易指出隐藏假设、边界条件和安全问题。
# Session A
claude "implement the payment webhook handler, write tests, commit when passing"
# Session B
claude "review the last commit on this branch as a staff engineer.
Check correctness, security, and edge cases.
Be harsh; this is going to production."这个模式在真实开发里非常有效。你可以用它审查 AI 写的代码,也可以审查自己写的代码。关键是让第二个 agent 没有原始实现过程的偏见。
MCP:让 Claude 接触真实世界
MCP,也就是 Model Context Protocol,是 Claude Code 连接外部系统的方式。数据库、GitHub、Jira、Slack、内部 API,只要有 MCP server,就可以变成 Claude 可调用的工具。
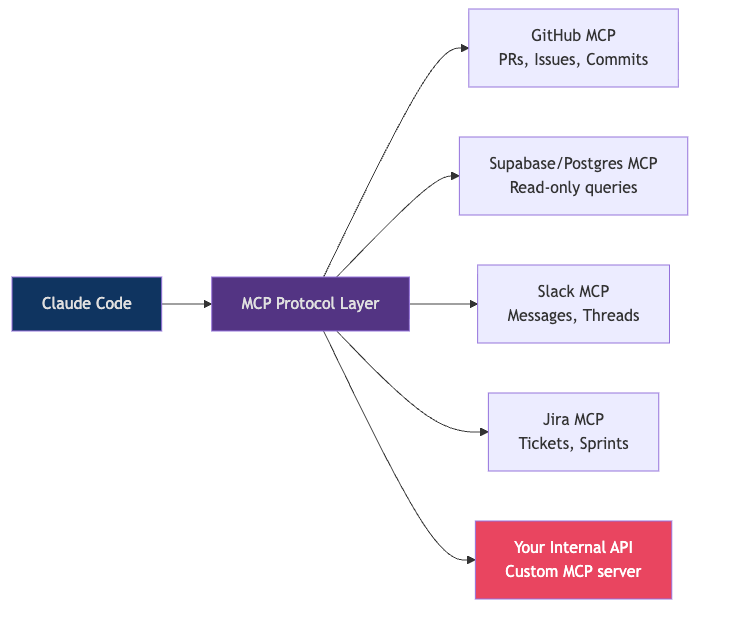
没有 MCP 时,你经常要复制粘贴:把 GitHub issue 贴给 Claude,把数据库 schema 贴给 Claude,把 CI 错误贴给 Claude。有 MCP 后,它可以自己读取这些上下文。
{
"mcpServers": {
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"],
"env": {
"GITHUB_TOKEN": "ghp_your_token_here"
}
},
"postgres": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-postgres"],
"env": {
"POSTGRES_CONNECTION_STRING": "postgresql://user:pass@localhost/mydb"
}
}
}
}但这里必须强调最小权限原则。默认应该只读。多数任务只需要 Claude 读数据库、读 issue、读 CI 结果,不需要写生产数据库。更安全的做法是准备两个配置:一个只读,用于分析和调试;一个读写,而且只连接开发环境,并且需要明确审批。
Skills 和 MCP 怎么选
很多人会问:应该写 skill,还是做 MCP server?原文给出的判断很清楚:
- 如果你要教 Claude 一套流程、规范、领域知识,用 skill。例如“我们公司如何发布到 Kubernetes”。
- 如果你要让 Claude 读取实时数据或执行外部动作,用 MCP。例如“查询当前生产数据库状态”。
- 不确定时,优先用 skill。Skill 是 Markdown,可以审查;MCP server 是可执行工具,风险更高。



