Ornith-1.0 发布:开源智能编程新王登场
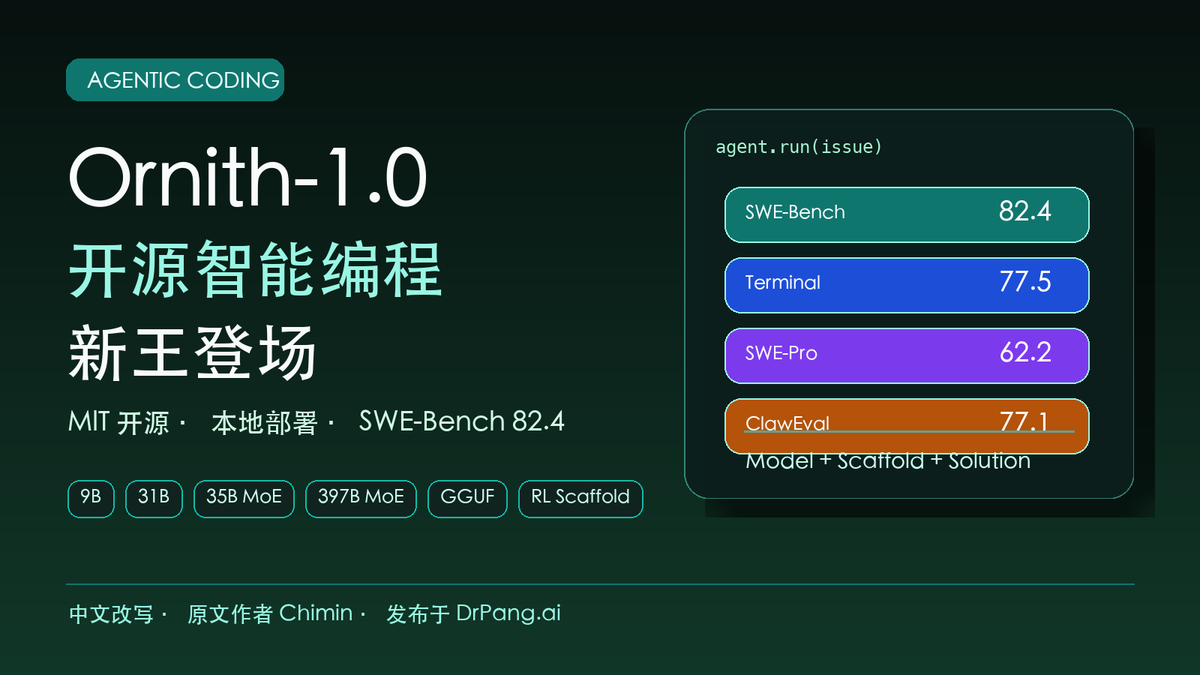
Ornith-1.0 以 MIT 开源发布,覆盖 9B 到 397B 多种规格,并在 SWE-Bench、Terminal-Bench、ClawEval 等 Agentic Coding 基准上给出亮眼成绩。
本文为中文改写与评论,原文作者 Chimin,原文发布于 Medium,时间为 2026 年 6 月 28 日,原文链接:Ornith-1.0 Released: A New King of Agentic Coding Ascends, Open-Sourced under MIT。本文保留原文核心结构与观点,并结合中文读者对 AI coding agent、开源模型和本地部署的关注做了重新组织。
在编程这件事上,开源模型已经不再只是追赶者,而是开始走到前面。

这不是夸张,也不是标题党。原文提到,名为 Ornith-1.0 的模型家族以开源形式发布,并在最硬核的 AI 编程赛道,也就是 Agentic Coding 上,横扫了多个公开基准。
SWE-Bench Verified:82.4。Terminal-Bench 2.1:77.5。SWE-Bench Pro:62.2。NL2Repo:48.2。ClawEval:77.1。
这不是“接近闭源模型水平”。原文的判断更激进:很多闭源模型甚至还没有公开达到这样的成绩。
换句话说,在编程能力上,开源模型已经从“追赶闭源”变成“在多个维度领先”。而且这一次,它不是单一尺寸的模型领先,而是覆盖多个参数规模、MIT 开源授权、可本地部署,甚至提供 GGUF 版本。
四个模型,一个野心
Ornith-1.0 不是一个单独模型,而是一个模型家族。它包含四个规格,从个人电脑到服务器集群都有对应选择:
- 9B Dense
- 31B Dense
- 35B MoE
- 397B MoE
最小的 9B 可以在消费级 GPU 上运行;最大的 397B MoE 面向企业级私有部署。它是在 Gemma 4 和 Qwen 3.5 基础上做 post-training,相当于站在已有开源巨人的肩膀上,再往前跳了一步。
这个布局很有意思。通常开源模型策略有两种:一种是小而精,比如 7B 模型用于走量;另一种是大而全,比如几百 B 模型负责展示肌肉。但 Ornith 从 9B 覆盖到 397B,每一档都没有简单放弃。
背后的逻辑很清楚:9B 给个人开发者,本地运行,零成本;31B 给小团队,一台服务器就能管理;35B MoE 给中等项目,强调效率;397B MoE 给大企业,私有部署,数据留在内部。
每一层都有明确用户场景。这不像是“发布一个模型”,更像是在“占领一条赛道”。
82.4 分到底意味着什么?
先看数据。
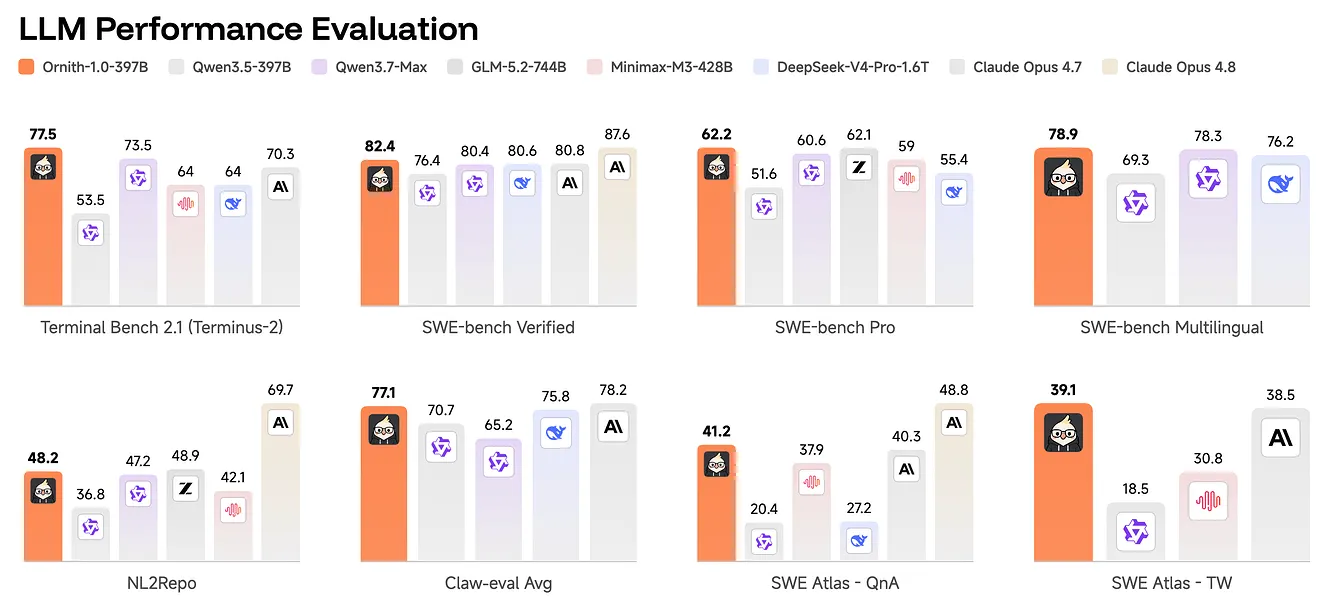
SWE-Bench Verified 目前是 Agentic Coding 最硬核的评测之一。它不是选择题,也不是补全题。它测试的是:给你一个真实 GitHub issue,模型需要自动定位代码、修改代码,并让所有单元测试通过。
这是真实软件工程任务,不是刷 LeetCode。
一个熟练人类开发者处理 SWE-Bench 任务时,行业里常见估计正确率大约在 70% 到 75%。当然这只是粗略共识,但足以说明难度:很多程序员第一次做 SWE-Bench 问题也未必能通过。
Ornith-1.0 达到了 82.4。
不是 82.4% 这个随便写出来的百分比,而是在该基准上的 82.4 分。按原文说法,这是目前公开可验证的最高水平之一。82.4 不只是一个数字,它更像是一份声明。
再看其他指标。
SWE-Bench Pro:62.2。 Pro 版本涉及多文件修改、跨模块重构和复杂依赖关系。62.2 意味着它已经具备处理中等规模工程任务的能力,不只是“改一行注释”这种演示级能力。
Terminal-Bench 2.1:77.5。 这个基准测试模型在真实终端环境里的操作能力:cd、ls、grep、修改配置文件、调试服务、部署应用。77.5 说明它不是在“模拟终端”,而是真的像坐在工作站前的工程师一样使用终端。
NL2Repo:48.2。 用自然语言描述需求,然后直接生成完整 GitHub 仓库。这个分数看起来不高,但你要理解任务难度:你说“帮我做一个任务管理应用”,它要构建整个项目。48.2 已经是开源模型中的高分。
此外还有 SWE Atlas 41.2 QnA、ClawEval 77.1。

把这些数字翻译成白话就是:Ornith-1.0 不是一个和你聊代码的聊天机器人。它更像一个能坐在你的工作站前、打开终端、理解代码库,并独立完成开发任务的 AI 工程师。
更关键的是,这个工程师免费,采用 MIT license,可以商用。
让模型改进自己的工具
最值得讨论的不是高分本身,而是它如何拿到这些分数。
Ornith-1.0 是基于 Gemma 4 和 Qwen 3.5 做 post-training,但关键创新在于一个技术决策:用强化学习同时优化两件事:任务 scaffold 和最终 solution。
这是什么意思?
传统 AI 编程工具架构通常有两层。第一层是 scaffold,负责任务规划、工具调用和上下文管理。第二层是 solution,负责真正写代码、修 bug、跑测试。
过去很多团队的做法是:scaffold 由人类工程师手写,规则固定;模型主要优化 solution,也就是实际写代码的那部分。
Ornith 的做法不同。它把 scaffold 和 solution 都放进强化学习优化循环,让模型自己发现“什么样的执行框架更好”,而不是让人类工程师凭经验猜。
这个差别有多大?有点像“给工人一把锤子,让他使用它”,和“让工人自己设计一把更顺手的锤子,然后再使用它”。由使用者自己设计出来的工具,天然更符合实际工作流。
用 Ornith 自己的说法,模型可以自主改进执行框架。翻译一下就是:AI 不只是写代码,AI 还在优化“写代码的方法”。
这件事的影响远超基准分数。因为它意味着未来 AI 编程工具的进化,不再完全受限于人类工程师对“好 scaffold”的想象。模型可以探索人类没想到的执行策略,也可能发现人类没有设计出来的工具组合。
人类后退一步,模型前进一步。强化学习飞轮一旦转起来,迭代速度会远远超过手工调参。
开源撕开闭源的最后一道防线
Coding agent 很长时间都被认为是闭源模型的最后堡垒。
原因很简单:这个任务太难。它不是简单预测下一个 token,而是要理解复杂代码仓库里的上下文,规划多步操作,调用各种工具,处理错误反馈,并反复修正方案。这和“写一段文字”完全不是一个难度等级。
也正因为如此,Anthropic 和 OpenAI 都在 coding agent 上押了重注。Claude Code 已经成为非常重要的商业化产品,GitHub Copilot 则拥有千万级用户。AI 编程是大模型商业化里最确定、最快产生收入的赛道之一。
闭源玩家的算盘很清楚:基础模型可以开源,你们随便用;但真正好用的 coding agent,要付费。
然后 Ornith-1.0 出现了:MIT 授权、GGUF 版本、本地部署、全参数范围、多个开源 benchmark 高分。
做模型的不如卖 agent 的,卖 agent 的又遇到开源直接免费送。这可能是当前 AI 编程领域最大的黑色幽默。
原文提到,Ornith 背后的团队并不是千人巨头。根据 Berry Xia 在 X 上的消息,这更像是一个基于现有开源模型做 post-training 的研究团队。没有天价融资新闻,没有“改变世界”的发布会幻灯片。只有一个模型家族、一组 benchmark 分数、MIT license,然后直接丢给开源社区。
你可以想象 Anthropic 和 OpenAI 的产品经理看到这个新闻时的心情。他们花了巨额资源在 Agentic Coding 上建立护城河。现在一个开源团队基于开源模型做 post-training,拿到多个公开高分,然后说:随便用,免费。
闭源花大钱修起来的护城河,被开源用一次 post-training 推平了一大块。
开源 vs 闭源:战场已经变了
我们先盘点一下当前局面。
开源阵营:Ornith-1.0(SWE-Bench 82.4)、DeepSeek V4(代码能力在行业里被广泛认可)、Qwen 3.5(代码能力显著跃升)。这些模型都采用 MIT 或类似宽松许可证,可以本地部署,也可以免费商用。
闭源阵营:Claude Code、GPT-5.5 + Codex、Gemini + Code Assist 等。闭源产品体验仍然强,但公开、可复现的 benchmark 数据并不总是完整透明。
一个关键细节是:闭源模型在 SWE-Bench 上的分数大多缺少完全公开、独立可复现的数据。Ornith 的分数公开发布,任何人都可以运行模型去验证。
当一个开源模型的 benchmark 更透明、分数更高、还完全免费时,市场会发生什么?
答案已经在其他赛道验证过。LLaMA 开源后,闭源基础模型的议价能力明显被削弱。Stable Diffusion 开源后,Midjourney 被迫从“卖模型”转向“卖体验”。
现在,同样的剧本正在 Agentic Coding 里上演。
而这一次,开源手里的武器更锋利。因为 Agentic Coding 的核心不只是模型能力,还有工程能力。工程能力恰恰是开源社区最擅长的。成千上万开发者基于 Ornith 二次开发,可以产生无数 agent framework 和垂直场景方案。闭源公司的工程团队再强,规模也很难和整个社区相比。
赛道已经变了:从“谁的模型更强”,变成“谁的生态更大”。闭源还在比模型,开源已经开始比生态。
三个信号
信号一:Agentic Coding 的模型层正在商品化
当 9B 模型就能具备 agent 级编程能力,当 MIT license 允许任何人免费商用,当 GGUF 版本让你可以在 MacBook 上运行,模型本身就不再是稀缺资源。就像云计算让物理服务器不再稀缺一样,真正有价值的东西会从“模型能力”转向“场景适配”和“工作流集成”。
谁能把 Ornith 接入你的内部代码仓库,接入 CI/CD 流程,并适配你的代码规范和业务逻辑,谁就能赚钱。模型本身反而不再收费。
信号二:强化学习联合优化 scaffold 和 solution 会成为新范式
Ornith 不是第一个用 RL 做 post-training 的模型。但它把“scaffold + solution 联合优化”做到非常极致,并用六个 benchmark 的成绩证明了有效性。
这意味着未来 AI 编程工具不再是“人类设计框架,模型执行指令”。更可能变成“模型设计自己的框架,模型自己执行,RL 提供反馈,模型再迭代框架”。一旦这个闭环形成,迭代速度会是指数级的。
信号三:开源第一次在 agent 时代拥有结构性优势
过去两年,开源模型已经在聊天、写作、翻译等内容生成场景证明了竞争力。但 Agentic Coding 是第一次:开源模型在复杂任务执行维度上跑到了非常靠前的位置。
这不是偶然。Agent 的核心是工具调用、多步规划和环境交互。这些问题的本质是工程问题。而工程问题天然适合开源协作。闭源公司可以隐藏模型权重,但很难隐藏最优工程架构。上千开发者一起打磨 agent framework,迟早会产生超过任何单一闭源团队设计的东西。
最后
Ornith-1.0 的发布让人想起一个老问题。
高盛分析 AI 行业时曾问过:更便宜的智能,到底会创造更多需求,还是摧毁定价能力?
当时这个问题讨论的是基础模型。现在,同一个问题必须放到 Agentic Coding 上重新问一遍。
当一个完全开源、全参数范围、可本地部署、开源性能最强之一的 Agentic Coding 模型家族,以 MIT license 出现在所有人面前时,“AI 写代码”的商业模式会发生什么?
Ornith 团队用行动给了一个答案:先别想那么多,先开源再说。