斯坦福大学的章鱼v2:为提升代理能力革新设备上的语言模型
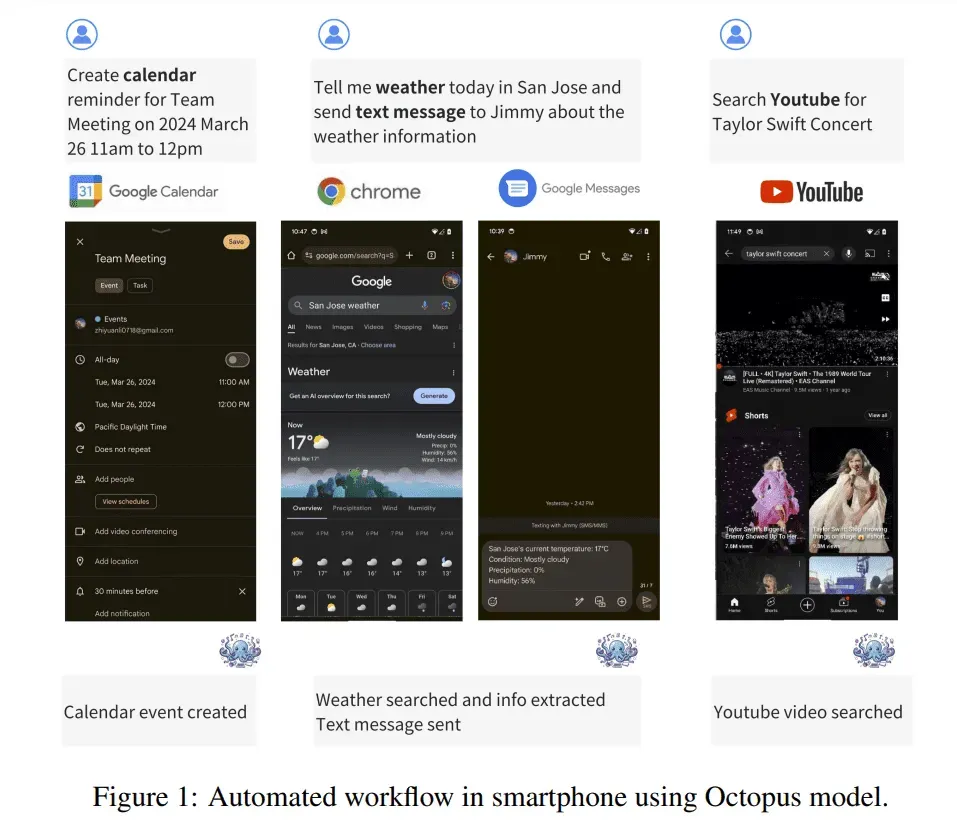
- 斯坦福大学推出章鱼v2,这是一个突破性的设备上语言模型,旨在解决现有模型相关的延迟、准确性和隐私问题。
- 章鱼v2大幅减少了设备上应用的延迟,并提高了准确性,效率和速度超过GPT-4,同时将上下文长度减少了95%。
- 方法论涉及对一个从Gemma 2B衍生的20亿参数模型进行微调,这个模型专注于针对Android API调用的定制数据集,并融入功能性令牌以精确调用函数。
- 章鱼v2在函数调用任务中实现了99.524%的惊人准确率,每次调用的延迟最小化到0.38秒,并且只需要5%的上下文长度进行处理。
主要AI新闻:
在人工智能(AI)领域,特别是在大型语言模型(LLMs)的领域,追求模型效率与现实世界限制(如隐私、成本和设备兼容性)之间平衡的需求一直是一个迫切的问题。尽管基于云的模型拥有卓越的准确性,但它们依赖于持续的互联网连接、潜在的隐私漏洞以及高昂的成本,提出了巨大的挑战。此外,在边缘设备上部署这些模型由于硬件限制而在维持最佳的延迟和准确性上引入了复杂性。
为了提升AI的效率和可访问性,已经进行了许多尝试,例如Gemma-2B、Gemma-7B和Llama-7B,以及像Llama cpp和MLC LLM这样的框架。像NexusRaven、Toolformer和ToolAlpaca这样的倡议已经推动了AI中函数调用的界限,努力模仿GPT-4的效果。像LoRA这样的技术简化了GPU限制下的微调。然而,这些努力都在努力解决一个关键瓶颈:特别是对于资源受限设备上低延迟、高准确性应用程序,实现模型大小和运行效率的和谐融合。
斯坦福大学的最新创新,章鱼v2,是一个先进的设备上语言模型,旨在解决当前LLM应用中与延迟、准确性和隐私相关的普遍挑战。与其前身不同,章鱼v2在设备上的应用中实现了显著的延迟减少和准确性提高。它的突破性方法围绕着使用功能性令牌进行微调,使得精确函数调用成为可能,并在效率和速度上超越GPT-4,同时将上下文长度减少了惊人的95%。
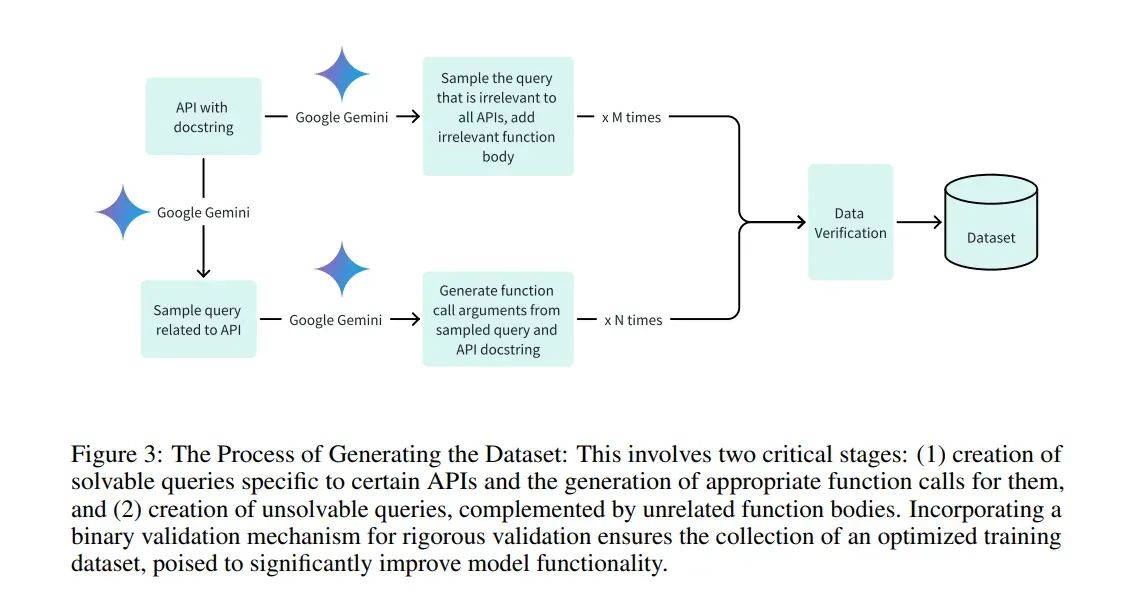
章鱼v2背后的方法论涉及对一个从Google DeepMind的Gemma 2B衍生的20亿参数模型进行微调,这个模型专注于针对Android API调用的精心策划的数据集。这个数据集包括正面和负面示例,以提高函数调用的精度。训练计划包括完整模型和低秩适应(LoRA)技术,以优化设备上执行的性能。创新的核心在于在微调过程中引入功能性令牌,这大大减少了延迟和上下文长度的需求。这一突破使得章鱼v2能够在边缘设备上实现函数调用的显著准确性和效率,而无需大量的计算资源。
在基准评估中,章鱼v2惊人地在函数调用任务中实现了99.524%的准确率,大大超过了GPT-4。此外,该模型展现出了显著的响应时间缩短,每次调用的延迟减少到仅0.38秒,与之前模型相比提高了35倍。更进一步,章鱼v2只需要5%的上下文长度进行处理,强调了它在处理设备上操作时的无与伦比的效率。这些指标凸显了章鱼v2在减轻操作需求的同时保持卓越性能水平方面的变革性进步,巩固了它作为设备上语言模型技术的重大进步的地位。
来源:Marktechpost Media Inc。
结论:
斯坦福的章鱼v2代表了设备上语言模型技术的重大飞跃。它在大幅减少延迟和上下文长度的同时提高准确性的能力,对各个市场,特别是那些依赖于有严格隐私和效率要求的AI应用的市场,有着深远的影响。章鱼v2的进步有望革新设备上AI的格局,提供无与伦比的性能,并为各行各业开辟创新解决方案的道路。



