什么是1位大语言模型(LLMs)? BitNet b1.58时代的1位LLMs
在人工智能界,最新加入的是1位大语言模型(LLMs)。你可能难以置信,但这能改变很多事情,并有望解决LLMs面临的一些主要挑战,特别是它们庞大的体积问题。
通常(不总是),不管是LLMs还是逻辑回归,机器学习模型的权重通常存储为32位或16位浮点数。这就是我们无法在个人电脑和生产环境中使用GPT或其他大型模型的原因,因为这些模型由于高精度权重而体积巨大。比如,假设我们有一个名为“MehulGPT”的LLM,它有70亿参数(类似于Mistral或Llama-7B),使用32位精度(每个4字节)。该模型将占用
总内存 = 单个权重大小 * 权重数
总内存 = 4字节 * 70亿
总内存 = 280亿字节
换算成千兆字节(GB):
总内存 = 280亿字节 / 1024³字节每GB
总内存 ≈ 26.09 GB
这个体积非常大,导致许多设备,包括手机,因为没有足够的存储或处理能力而无法使用它。
那么如何让小型设备和手机也能使用LLMs呢?
1位LLMs
在1位大语言模型中,与传统LLMs的32/16位不同,权重参数只用1位(即0或1)来存储。这大大减小了总体积,使得即使是小型设备也能够使用LLMs。假设“MehulGPT”的1位版本,这次占用的内存是
总内存 = 单个权重大小 * 权重数
总内存 = 0.125字节 * 70亿
总内存 = 8.75亿字节
换算成千兆字节(GB):
总内存 = 8.75亿字节 / 1024³字节每GB
总内存 ≈ 0.815 GB
1位 = 0.125字节
因此,大量节省了计算和存储资源。
这类似于量化吗?
量化是通过降低权重的精度来减少模型大小的方法,例如,从32位降到8位,从而将大小减少4倍。使用的位数越少,模型尺寸就越小,但可能会影响性能。
1位大语言模型与量化的概念相似,但有所区别。量化是减少精度(例如,如果权重值是2.34567890656373…,它可能被简化为2.3456)。
而在1位大语言模型中,每个权重仅由二进制数(0或1)表示,进一步减小了模型大小。与传统LLMs相比,为了不牺牲性能,进行了一些重大架构更改。
BitNet b1.58
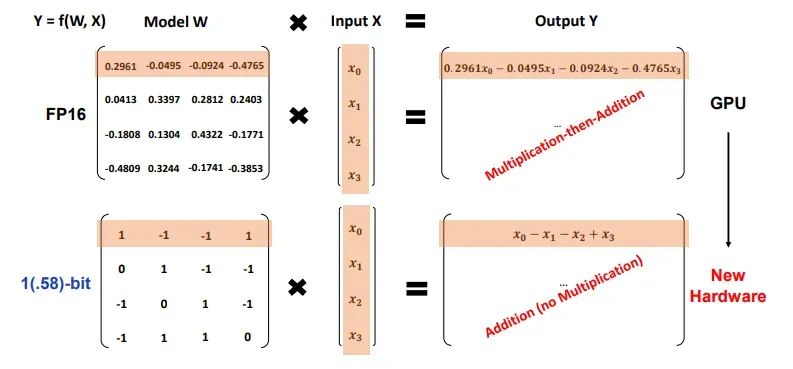
目前第一个此类模型,BitNet b1.58,每个权重使用1.58位(因此不是精确的1位LLM),一个权重可以有三个可能值(-1,0,1)。
对于1.58位,1) 权重只有-1,0,1值 2) 由于值只有-1,0,1,不需要乘法操作
据论文称:
BitNet b1.58在复杂度和任务性能上与16位浮点LLM基准相匹配。
它提供更快的处理速度,相比传统模型使用更少的GPU内存。
模型减少了矩阵乘法的乘法操作,提高了优化和效率。
包括用于系统级优化的量化功能,并整合了LLaMA中使用的RMSNorm和SwiGLU等组件。
注意:为了简化解释,我暂时略过上述术语。
这个模型目前还未公开,因此还未经过普通用户测试。但如果其声明为真,那我们即将迎来一场盛宴!
Source: https://medium.com/data-science-in-your-pocket/what-are-1-bit-llms-3f2ae4b40fdf



