什么是 Loop Engineering?它和 Harness Engineering 有什么不同?
Loop Engineering 不是把所有脚本换成大模型,而是在 agent harness 之上设计自动触发、状态持久化、maker/checker 分工和可验证停止条件的控制循环。

本文为中文改写与评论,原文作者 Akshay Kokane,发布于 Level Up Coding / Medium,原文链接:What is Loop Engineering? How it is different than Harness Engineering?。本文保留原文的核心结构和论点,并结合中文读者对 Claude Code、Codex、自动化循环和 agent harness 的实际使用场景重新组织。
Loop Engineering 的关键,不是把所有脚本都换成大模型,而是把“谁来提示 agent、何时提示、如何检查结果”这一层从人手里抽出来,变成一个可运行、可观察、可停止的系统。
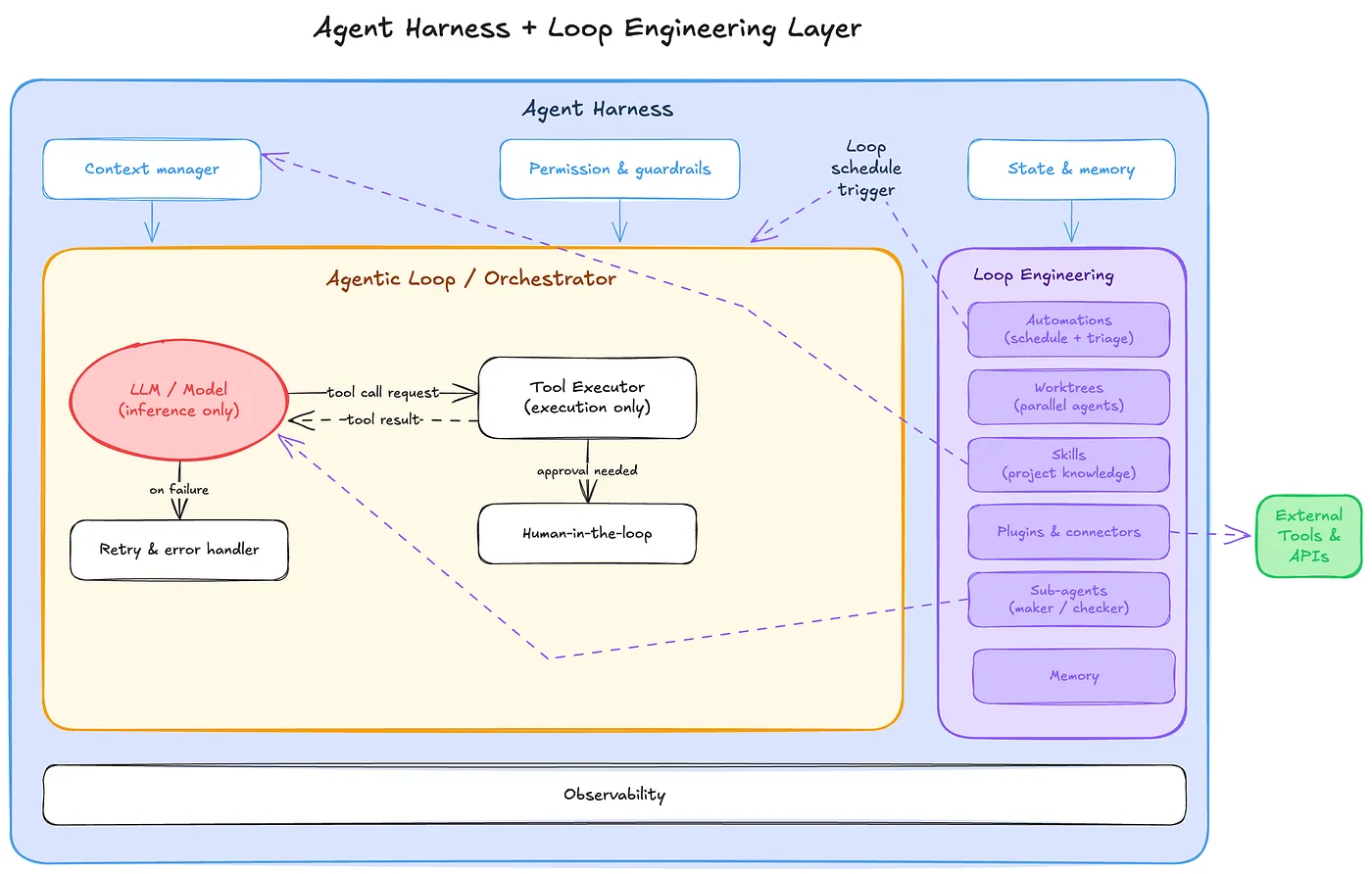
过去一年,AI 工具圈很喜欢给旧模式起新名字。Context engineering、agent harness、agentic workflow、loop engineering,一个接一个出现。很多词确实有营销味道,但原文作者提醒我们:这次不要太快把它当成纯 hype,因为这里面有一个真实变化。
这个变化可以用一句话概括:过去你直接写 prompt 给 agent;现在你开始设计一个系统,让这个系统在合适的时间、带着合适的上下文,自动去提示 agent,并持续检查它是否完成目标。
这听起来像 cron job、工作流引擎、CI pipeline、事件驱动系统。它们当然相似。真正不同的是,循环内部有一个会在运行时判断下一步的模型。传统 cron job 的步骤在写代码时就固定了:查数据库、写文件、发邮件。Loop Engineering 里的循环可能只写着“分析昨天失败的 CI”,然后由模型判断哪些失败值得处理、该先看哪个、尝试什么修复、什么时候停下来。
这不是革命,但确实不是普通脚本。它把“动态判断”放进了自动化循环。
Loop Engineering 到底是什么?
原文引用 Peter Steinberger 的定义:Loop Engineering 是把你自己从“不断提示 agent 的人”这个位置上替换掉,转而设计一个会替你提示 agent 的系统。Claude Code 负责人 Boris Cherny 也表达过类似观点:他不再手动 prompt Claude,而是让 loops 去 prompt Claude、判断下一步做什么;他的工作变成写 loops。
这句话容易被误读成“以后别写 prompt 了”。更准确的理解是:prompt 仍然存在,但它从一次性的对话输入,变成循环系统的一部分。你设计的是循环的触发条件、上下文输入、工具权限、状态存储、停止条件和结果审查,而不是只设计一句漂亮提示词。
一个简单例子是每日 CI 分诊。手动模式下,工程师打开 CI dashboard,挑几个失败,问 Claude/Codex 看日志、找原因、尝试修复。Loop 模式下,系统每天自动读取失败记录,把仓库、日志、最近提交、相关测试一起交给 agent,然后让 maker agent 尝试修复,再让 checker agent 判断结果是否安全、是否需要开 PR、是否要通知人类。
这就是“人提示 agent”到“系统提示 agent”的层级上移。
怀疑是合理的
原文最好的地方,是没有把 Loop Engineering 写成万能答案。相反,它先承认几个怀疑点。
第一,术语确实膨胀。 每隔几个月,行业就会出现一个新复合名词。很多时候,它只是旧系统设计模式披上 AI 外衣。合理的默认态度不是立刻相信新词,而是先看概念底下到底变了什么。
第二,成本问题很现实。 一个定时运行、并行启动多个 sub-agent、不断迭代直到目标满足的 loop,token 消耗可能非常不稳定。很多团队只是想检查部署状态,这种事写一个 Python 脚本或 bash check 就够了。为了让前沿模型每 15 分钟“思考一下”而付费,通常不划算。
第三,demo 往往挑得很聪明。 Daily CI triage、commit briefing、从上周提交里找 bug,这些任务正好需要模型的动态判断,所以看起来很适合 loop。但这不代表所有自动化都应该换成 loop。Loop 只在任务需要运行时推理、无法完全预先写死决策逻辑时才有优势。
换句话说,Loop Engineering 的价值不在于“比脚本高级”,而在于它能处理脚本很难提前枚举的判断。
Harness Engineering 和 Loop Engineering 的关系
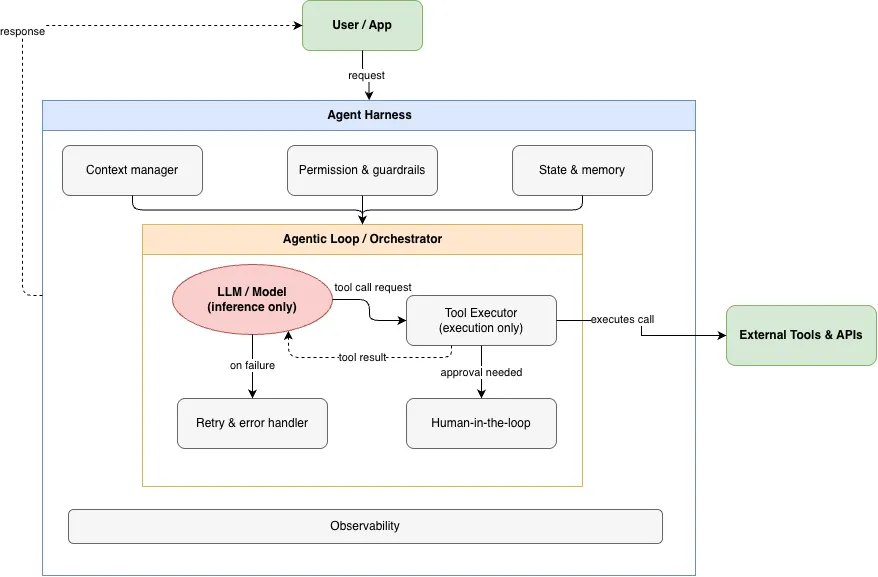
Harness Engineering 解决的是一个 agent 在什么环境里运行。它负责上下文管理、工具权限、重试、日志、状态持久化、错误恢复,以及模型调用之间的边界。你可以把 harness 理解成一个 agent 的“运行容器”。它让单个 agent 不至于 40 轮之后忘记目标,不至于乱调用工具,也不至于自信地输出错误结果却没人发现。
Loop Engineering 站在 harness 上面。它关心的是多个 agent、多次运行、跨时间的编排。它回答的问题是:谁发现工作?谁执行工作?谁检查工作?今天做完的事情,明天的循环怎么知道?如果多个 agent 并行工作,它们如何隔离?如果某个结果不可信,谁把它退回?
所以,两者不是替代关系。Harness 是单个 agent 的执行环境,loop 是决定何时启动 agent、启动哪个 agent、给它什么任务、如何处理输出的控制平面。你需要二者,只是它们解决不同层级的问题。
一个 loop 的结构组件
原文借用 Addy Osmani 的总结,把 loop 拆成几个结构件:
- Automations:定时或事件触发的提示,把工作浮上来。Claude Code 里可以是
/loop、/goal和 scheduled tasks;Codex App 里则对应 Automations 与 Triage inbox 这类能力。 - Worktrees:给并行 agent 提供隔离。两个 agent 同时改同一个文件,本质上和两个工程师无协调地改同几行代码一样危险。
- Skills:把项目知识写在对话之外,让 agent 每次运行时不必重新推断团队约定、架构规则和代码风格。
- Connectors:通过 MCP 等集成连接真实环境,让 loop 能开 PR、更新 ticket、发 Slack/飞书消息、读 CI 或 issue。
- Sub-agents:maker/checker 分工。写代码的 agent 不应该是唯一判断自己是否写对的人。
- State:这是整套系统的脊柱。可以是 markdown 文件、Linear board、GitHub issue、数据库记录。模型会忘,repo 和外部状态不会。
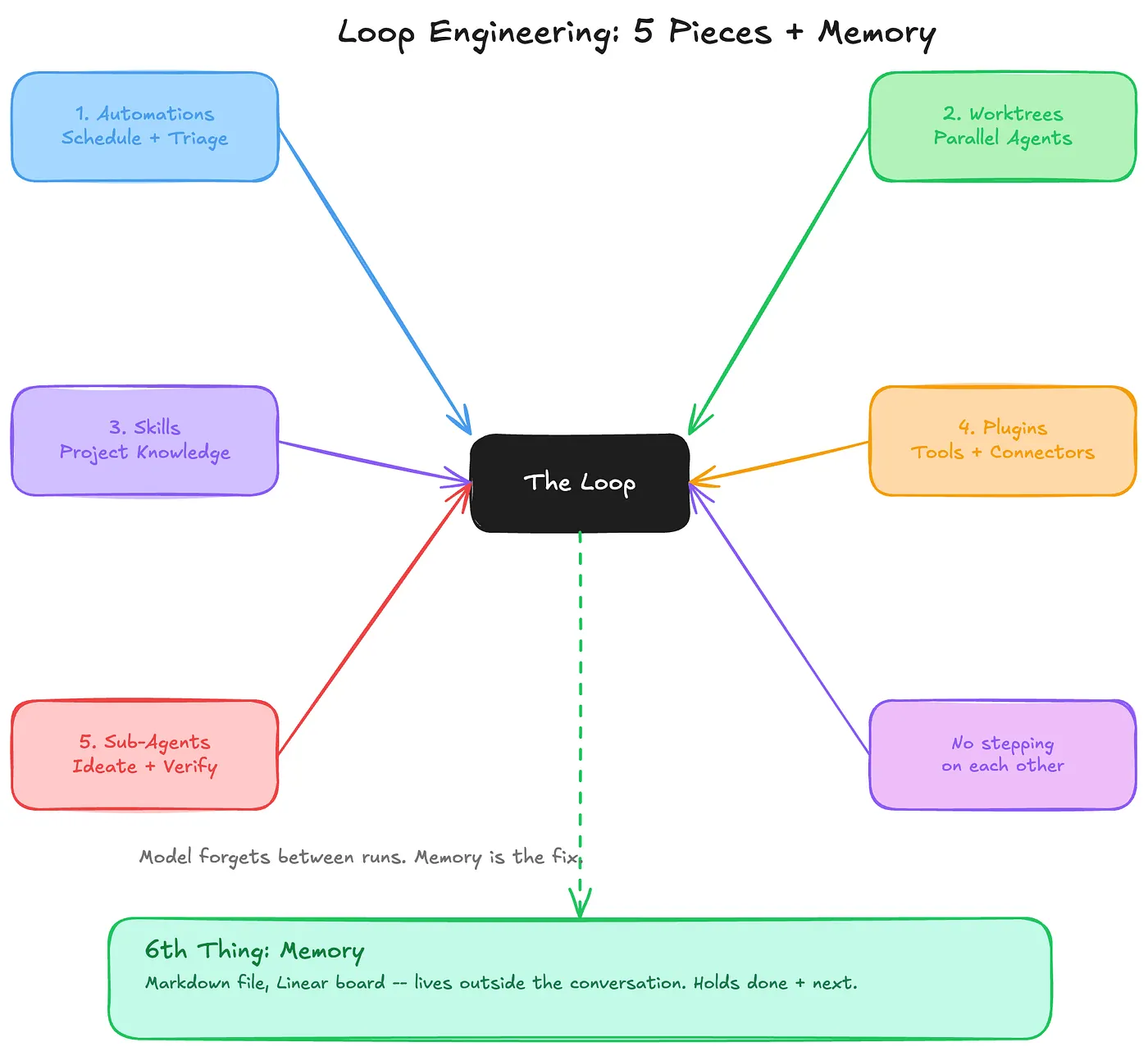
/loop 的工作方式示意。如果没有 state,loop 很容易变成“每天重新开始的一次性 agent 调用”。真正的长期自动化,需要知道上次尝试了什么、哪些通过了、哪里还没完成、谁审过、下一步是什么。
/goal 为什么值得特别关注
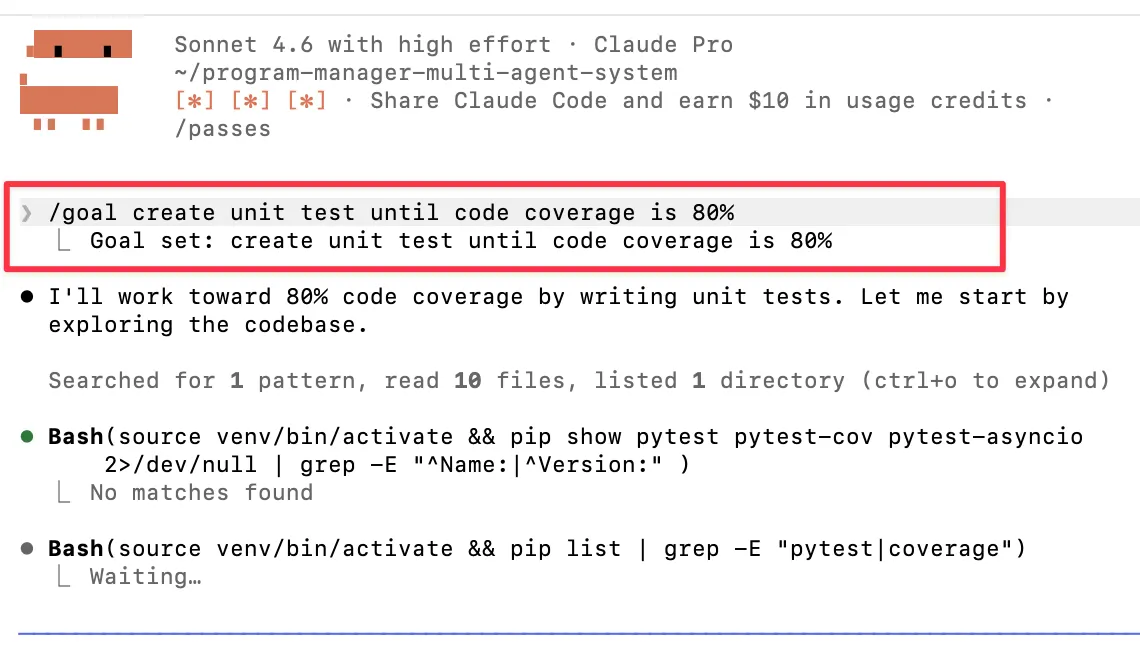
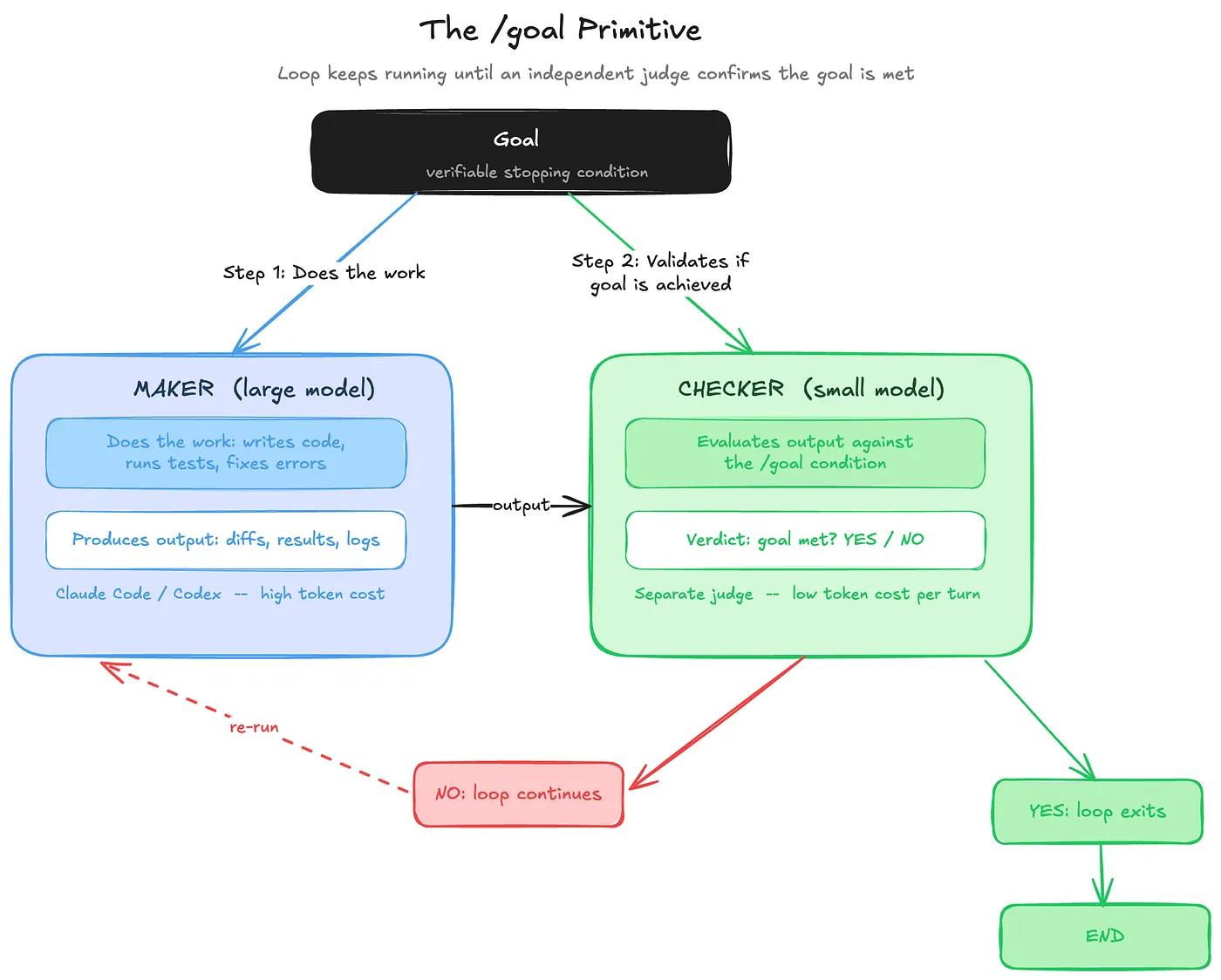
/goal 的关键不是循环本身,而是可验证停止条件和独立检查。大多数 loop 组件都有旧世界的对应物:定时任务、队列、工作树、状态机、工作流引擎。但 /goal 这个 primitive 比较新。
你给系统一个可验证的停止条件,例如:“test/auth 下所有测试通过,并且 lint 干净。”Loop 会持续运行,直到这个条件为真。更关键的是,完成判断不是由刚刚做事的 agent 自己给自己打分,而是由另一个更小或独立的模型来评估目标是否满足。
这就是 maker/checker 分工应用到“停止条件”本身。传统 cron job 在脚本退出时停止;这个 loop 在独立 judge 确认规格满足时停止。
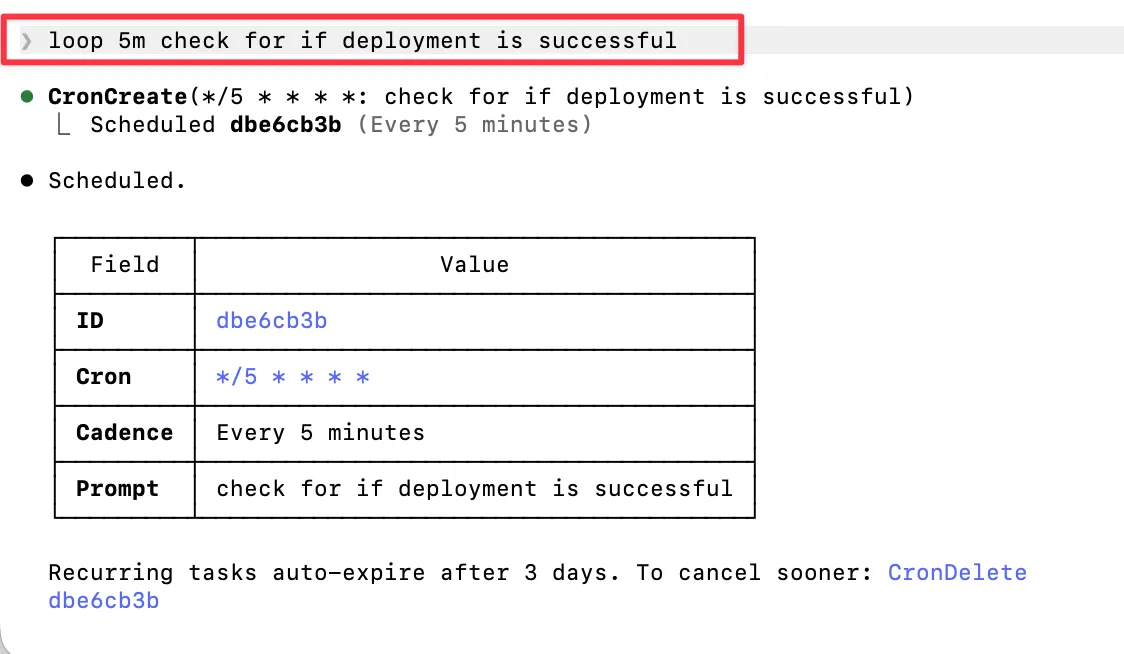
/goal 的工作方式示意。这是否值得花 token,取决于问题。如果问题是“CI 是否通过”,bash check 更便宜、更可靠。如果问题是“这个 PR 按照我们的安全约定是否可以合并”,模型判断可能值得付费。关键不是用不用模型,而是判断的模糊度是否真的需要模型。
诚实结论
Loop Engineering 不是一个全新的范式。它更像是建立在 agent harness primitives 之上的编排模式,用来处理跨时间、多 agent、自主执行的工作。
真正新的部分,是 /goal 这类停止条件 primitive,以及 maker/checker 分工被放到“是否完成目标”的判断上。这一点不太能直接映射到传统 reactive workflow、cron job 或普通 CI pipeline。
被夸大的部分,是“你应该停止提示 agent,开始设计 loops”这类泛化说法。对某些问题,这是正确方向;对大多数人第一时间想套进去的问题,它会浪费复杂度和 token。
原文用了一个很好的类比:你不会因为微服务存在,就把每个函数调用都改成微服务。只有当扩展性、隔离性和组织复杂度值得付出代价时,微服务才合理。Loop 也是一样。
从概念到生产
Loop Engineering 还太新,暂时没有成熟的生产手册。最稳妥的路径不是从“我要做一个 loop 平台”开始,而是先找一个反复出现、运行时决策确实模糊、脚本无法预先写死的工作流。
先让人带着 agent 手动跑几次。观察它在哪里失败、哪里需要判断、哪里产出的东西必须有人审、哪里只是浪费 token。那些观察结果,才是 loop design 的真实输入。
如果一个任务可以用确定性脚本解决,就用脚本。如果一个任务需要模型在运行时综合上下文、判断优先级、选择路径、并且结果可以被外部状态或独立 checker 验证,那才值得设计 loop。
最终的原则很简单:先把 harness 做稳,再在真正需要跨时间、自主编排和动态判断的地方构建 loop。