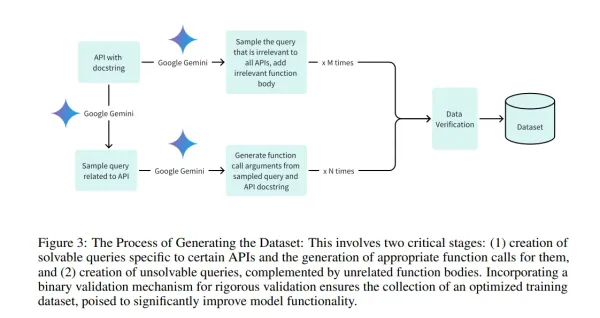
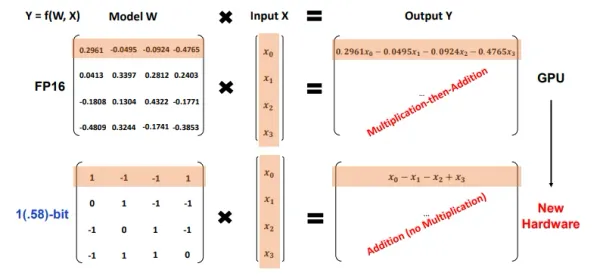
AI development
到2030年,AI可能会取代全球三亿个工作岗位
DEI支持者能否重新调整方向,引领人类走出困境? 作者:R. Wayne Branch博士 发表于 Fourth Wave 阅读时间:6分钟 我一直想写关于AI对多样性影响的文章。一次与一位建筑师朋友的偶然对话让我找到了写作的基础。这次对话是关于未来的工作和生活,尤其是被资本主义边缘化的人的生活。我问他:“你有没有想过AI会如何改变你的工作?”他三十出头,已经建立了一个成功的建筑公司。令我惊讶的是,他认为AI对人类的益处超过了他将采取的维持业务运行的适应策略。他真是令人鼓舞。 我们对未来建筑和设计的看法 假设你想建一栋房子或商业建筑。从你的桌面、笔记本电脑、手持设备或智能电视上调出众多AI平台之一,然后说:“我想建一栋房子。”平台的悦耳声音问:“在哪里,什么时候,预算多少?”或者你的已知账户、信用评分和消费习惯被扫描,它可能会告诉你:“看起来你有这么多钱可以花费。是这样吗?”然后,一系列提示会引导你思考你的项目(卧室数量、浴室、材料等)。 同时,符合代码的计划被计算出来。包括许可机构、金融机构和供应商在内的集成AI系统将相互对接。它们自己的AI平台管理供应链网络和库存管理系统